This post is the second and last part of a double entry about how SVMs work (theoretical, in practice, and implemented). You can check the first part, SVM – Support Vector Machine explained with examples.
Index
- Introduction
- Optimization and Quadratic Programming
- Sequential Minimal Optimization (SMO) algorithm
- Algorithm
- Results
Introduction
Since the algorithm uses Lagrange to optimize a function subject to certain constrains, we need a computer-oriented algorithm to implement SVMs. This algorithm called Sequential Minimal Optimization (SMO from now on) was developed by John Platt in 1998. Since it is based on Quadratic Programming (QP from now on) I decided to learn and write about it. I think it is not strictly necessary to read it, but if you want to fully understand SMO, it is recommended to understand QP, which is very easy given the example I will briefly describe.
Optimization and Quadratic Programming
QP is a special type of mathematical optimization problem. It describes the problem of optimizing (min or max) a quadratic function of several variables subject to linear constraints on these variables. Convex functions are used for optimization since they only have one optima which is the global optima.
Optimality conditions:

If it is a positive definite, we have a unique global minimizer. If it is a positive indefinite (or negative), then we do not have a unique minimizer.
Example
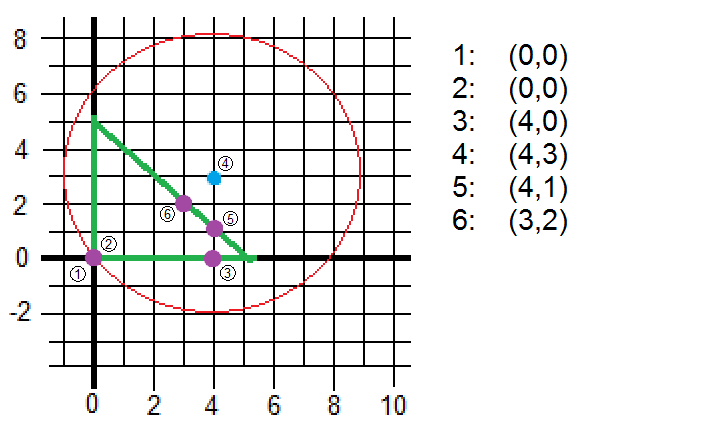
Minimize


Initial point (where we start iterating)
Initial active set 

Since a quadratic function looks like:

We have to configure the variables as:

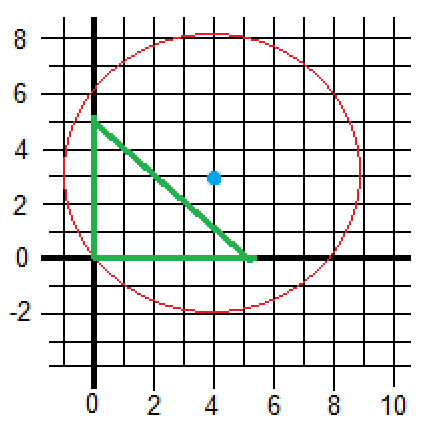
Iteration 1

Solve EQP defined by 

Now it is necessary to check whether this solution is feasible:


It is clear that this point was going to be feasible because the point (0,0) is where we started.
Now, we remove a constraint with negative 

Graphically, we started on (0,0) and we have to move to the same point (0,0). The removal of the constraint indicates to which axis and direction we are going to move: up or right. Since we took the first constraint out, we will move to the right. Now we need to minimize constrained to the second constraint.
Iteration 2

Solve EQP defined with
![A = \begin{bmatrix}<br /> 0 & -1<br /> \end{bmatrix} \quad b = [0]](https://s0.wp.com/latex.php?latex=A+%3D+%5Cbegin%7Bbmatrix%7D%3Cbr+%2F%3E++++++++0+%26+-1%3Cbr+%2F%3E++++++%5Cend%7Bbmatrix%7D+%5Cquad+b+%3D+%5B0%5D&bg=ffffff&fg=000&s=0&c=20201002)

Check whether this is feasible: 


Iteration 3

Solve EQP defined with
![A = [] \quad b = []](https://s0.wp.com/latex.php?latex=A+%3D+%5B%5D+%5Cquad+b+%3D+%5B%5D&bg=ffffff&fg=000&s=0&c=20201002)

Check whether this is feasible:

It is not feasible. 3rd constrained is violated (that is why the third element is 0). As it is not feasible, we have to maximize



So,

Finally we add the constraint that was violated.

Iteration 4

Solve EQP defined with
![A = \begin{bmatrix}<br /> 1 & 1<br /> \end{bmatrix} \quad b = [5]](https://s0.wp.com/latex.php?latex=A+%3D+%5Cbegin%7Bbmatrix%7D%3Cbr+%2F%3E++++++++1+%26+1%3Cbr+%2F%3E++++++%5Cend%7Bbmatrix%7D+%5Cquad+b+%3D+%5B5%5D&bg=ffffff&fg=000&s=0&c=20201002)

Check whether this is feasible:


Iterations and steps are drawn on the plane below. It is graphically easy to see that the 4th step was illegal since it was out of the boundaries.
Sequential Minimal Optimization (SMO) algorithm
SMO is an algorithm for solving the QP problem that arises during the SVM training. The algorithm works as follows: it finds a Lagrange multiplier 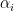


Because 


Let 


We want to optimize:
![L = \frac{1}{2} \| w \| ^2 - \sum \alpha_i [y_i (\overrightarrow{w} \cdot \overrightarrow{x_i} +b)-1] = \sum \alpha_i - \frac{1}{2} \sum_i \sum_j \alpha_i \alpha_j y_i y_j \overrightarrow{x_i} \cdot \overrightarrow{x_j}](https://s0.wp.com/latex.php?latex=L+%3D+%5Cfrac%7B1%7D%7B2%7D+%5C%7C+w+%5C%7C+%5E2+-+%5Csum+%5Calpha_i+%5By_i+%28%5Coverrightarrow%7Bw%7D+%5Ccdot+%5Coverrightarrow%7Bx_i%7D+%2Bb%29-1%5D+%3D+%5Csum+%5Calpha_i+-+%5Cfrac%7B1%7D%7B2%7D+%5Csum_i+%5Csum_j+%5Calpha_i+%5Calpha_j+y_i+y_j+%5Coverrightarrow%7Bx_i%7D+%5Ccdot+%5Coverrightarrow%7Bx_j%7D&bg=ffffff&fg=000&s=0&c=20201002)
If we pull out 
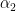

Let 

It represents the original formula 

Let 



Now we substitute in our original formula with 
Note that here we assume that


Now we substitute using


The first 


Constant terms are grouped and 

Let 




Since 

Therefore, the objective function is:

First derivative:

Second derivative:

Note that 

This is important to understand because when we want to use other kernels this has to be true.


Therefore, this is the formula to get a maximum:

While performing the algorithm, after calculating 
So we have that:
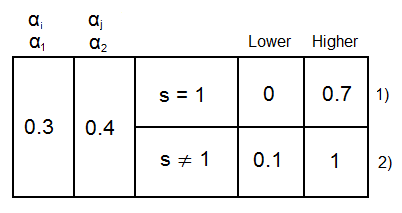
If 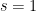
If 
If ![\gamma < C[/latex], then [latex]\text{min} \quad \alpha_2 = 0, \text{max} \quad \alpha_2 = \gamma[/latex]</span><br /> If [latex]s=-1](https://s0.wp.com/latex.php?latex=%5Cgamma+%3C+C%26%2391%3B%2Flatex%26%2393%3B%2C+then+%26%2391%3Blatex%26%2393%3B%5Ctext%7Bmin%7D+%5Cquad+%5Calpha_2+%3D+0%2C+%5Ctext%7Bmax%7D+%5Cquad+%5Calpha_2+%3D+%5Cgamma%26%2391%3B%2Flatex%26%2393%3B%3C%2Fspan%3E%3Cbr+%2F%3E+If+%5Blatex%5Ds%3D-1&bg=ffffff&fg=000&s=0&c=20201002)
If 
If





![\gamma < 0[/latex], then [latex]\text{min} \quad \alpha_2 = - \gamma, \text{max} \quad \alpha_2 = C[/latex]</span></p> <p>In other words: (L = lower bound, H = higher bound)<br /> [latex]<br /> \text{If} \quad y^{(i)} \neq y^{(j)}, L = max(0,\alpha_j - \alpha_i), H = min(C, C+ \alpha_j - \alpha_i) \\<br /> \text{If} \quad y^{(i)} = y^{(j)}, L = max(0,\alpha_i + \alpha_j - C), H = min(C, \alpha_i + \alpha_j)<br />](https://s0.wp.com/latex.php?latex=%5Cgamma+%3C+0%26%2391%3B%2Flatex%26%2393%3B%2C+then+%26%2391%3Blatex%26%2393%3B%5Ctext%7Bmin%7D+%5Cquad+%5Calpha_2+%3D+-+%5Cgamma%2C+%5Ctext%7Bmax%7D+%5Cquad+%5Calpha_2+%3D+C%26%2391%3B%2Flatex%26%2393%3B%3C%2Fspan%3E%3C%2Fp%3E+%3Cp%3EIn+other+words%3A+%28L+%3D+lower+bound%2C+H+%3D+higher+bound%29%3Cbr+%2F%3E+%5Blatex%5D%3Cbr+%2F%3E+%5Ctext%7BIf%7D++%5Cquad+y%5E%7B%28i%29%7D+%5Cneq+y%5E%7B%28j%29%7D%2C+L+%3D+max%280%2C%5Calpha_j+-+%5Calpha_i%29%2C+H+%3D+min%28C%2C+C%2B+%5Calpha_j+-+%5Calpha_i%29+%5C%5C%3Cbr+%2F%3E+%5Ctext%7BIf%7D++%5Cquad+y%5E%7B%28i%29%7D+%3D+y%5E%7B%28j%29%7D%2C+L+%3D+max%280%2C%5Calpha_i+%2B+%5Calpha_j+-+C%29%2C+H+%3D+min%28C%2C+%5Calpha_i+%2B+%5Calpha_j%29%3Cbr+%2F%3E+&bg=ffffff&fg=000&s=0&c=20201002)
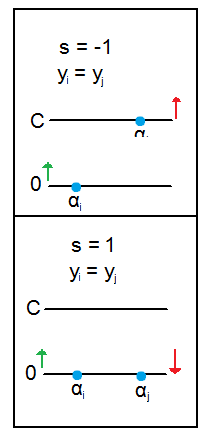
Why do we need to clip our
We can understand it using a very simple example.
Remember that if 





If 
1) As explained before, and taking into account that 

2) If they are different,
Remember that the reason why
|
||||||||||
If  , it means that we cannot balance or proportionally increase/decrease at all between and . In this case, we skip this , it means that we cannot balance or proportionally increase/decrease at all between and . In this case, we skip this  combination and try a new one. combination and try a new one. |
After updating


The change in the threshold can be computed by forcing ![E_1^{new} = 0 \text{ if } 0 < \alpha_1^{new} < C \text{(or } E_2^{new} = 0 \text{ if } 0 < \alpha_2^{new} < C \text{)}[/latex] [latex]E (x,y)^{new} = 0 \\ E(x,y)^{old} + \Delta E (x,y) = E (x,y)^{old} + \Delta \alpha_1 y_1 \overrightarrow{x_1}^T \overrightarrow{x} + \Delta \alpha_2 y_2 \overrightarrow{x_2}^T \overrightarrow{x} - \Delta b[/latex] So we have: [latex]\Delta b = E(x,y)^{old} + \Delta \alpha_1 y_1 \overrightarrow{x_1}^T \overrightarrow{x} + \Delta \alpha_2 y_2 \overrightarrow{x_2}^T \overrightarrow{x}[/latex] <h2><a name="alg">Algorithm</a></h2> <p>The code I provide in the <a href="http://laid.delanover.com/source-code/">Source code</a> section was developed by me, but I followed the algorithm shown in [1]. I will copy the algorithm here since it made my life really easier and avoided me many headaches for sure. All the credit definitely goes to the writer.</p> <p><b>Algorithm: Simplified SMO</b><br /> Note: if you check [1] you will see that this algorithm differs from the original one written on that paper. The reason is because the original one had mistakes that I wanted to fix and improve. I talk about that in <a href="http://laid.delanover.com/svm-algorithm-improvements/">this post</a>.</p> <p><b>Input:</b><br /> <span style="margin-left:20px">C: regularization parameter</span><br /> <span style="margin-left:20px">tol: numerical tolerance</span><br /> <span style="margin-left:20px">max_passes: max # of times to iterate over [latex]\alpha](https://s0.wp.com/latex.php?latex=E_1%5E%7Bnew%7D+%3D+0+%5Ctext%7B+if+%7D+0+%3C+%5Calpha_1%5E%7Bnew%7D+%3C+C+%5Ctext%7B%28or+%7D+E_2%5E%7Bnew%7D+%3D+0+%5Ctext%7B+if+%7D+0+%3C+%5Calpha_2%5E%7Bnew%7D+%3C+C+%5Ctext%7B%29%7D%26%2391%3B%2Flatex%26%2393%3B++%26%2391%3Blatex%26%2393%3BE+%28x%2Cy%29%5E%7Bnew%7D+%3D+0+%5C%5C+E%28x%2Cy%29%5E%7Bold%7D+%2B+%5CDelta+E+%28x%2Cy%29+%3D+E+%28x%2Cy%29%5E%7Bold%7D+%2B+%5CDelta+%5Calpha_1+y_1+%5Coverrightarrow%7Bx_1%7D%5ET+%5Coverrightarrow%7Bx%7D+%2B+%5CDelta+%5Calpha_2+y_2+%5Coverrightarrow%7Bx_2%7D%5ET+%5Coverrightarrow%7Bx%7D+-+%5CDelta+b%26%2391%3B%2Flatex%26%2393%3B++So+we+have%3A++%26%2391%3Blatex%26%2393%3B%5CDelta+b+%3D+E%28x%2Cy%29%5E%7Bold%7D+%2B+%5CDelta+%5Calpha_1+y_1+%5Coverrightarrow%7Bx_1%7D%5ET+%5Coverrightarrow%7Bx%7D+%2B+%5CDelta+%5Calpha_2+y_2+%5Coverrightarrow%7Bx_2%7D%5ET+%5Coverrightarrow%7Bx%7D%26%2391%3B%2Flatex%26%2393%3B++++%3Ch2%3E%3Ca+name%3D%22alg%22%3EAlgorithm%3C%2Fa%3E%3C%2Fh2%3E+%3Cp%3EThe+code+I+provide+in+the+%3Ca+href%3D%22http%3A%2F%2Flaid.delanover.com%2Fsource-code%2F%22%3ESource+code%3C%2Fa%3E+section+was+developed+by+me%2C+but+I+followed+the+algorithm+shown+in+%5B1%5D.+I+will+copy+the+algorithm+here+since+it+made+my+life+really+easier+and+avoided+me+many+headaches+for+sure.+All+the+credit+definitely+goes+to+the+writer.%3C%2Fp%3E+%3Cp%3E%3Cb%3EAlgorithm%3A+Simplified+SMO%3C%2Fb%3E%3Cbr+%2F%3E+Note%3A+if+you+check+%5B1%5D+you+will+see+that+this+algorithm+differs+from+the+original+one+written+on+that+paper.+The+reason+is+because+the+original+one+had+mistakes+that+I+wanted+to+fix+and+improve.+I+talk+about+that+in+%3Ca+href%3D%22http%3A%2F%2Flaid.delanover.com%2Fsvm-algorithm-improvements%2F%22%3Ethis+post%3C%2Fa%3E.%3C%2Fp%3E+%3Cp%3E%3Cb%3EInput%3A%3C%2Fb%3E%3Cbr+%2F%3E+%3Cspan+style%3D%22margin-left%3A20px%22%3EC%3A+regularization+parameter%3C%2Fspan%3E%3Cbr+%2F%3E+%3Cspan+style%3D%22margin-left%3A20px%22%3Etol%3A+numerical+tolerance%3C%2Fspan%3E%3Cbr+%2F%3E+%3Cspan+style%3D%22margin-left%3A20px%22%3Emax_passes%3A+max+%23+of+times+to+iterate+over+%5Blatex%5D%5Calpha&bg=ffffff&fg=000&s=0&c=20201002)

Output:


Algorithm:
Initialize
Initialize
Calculate 


![\text{while} ((\exists x \in \alpha | x = 0 ) \text{ } \& \& \text{ } (\text{counter} < \text{max\_iter}))[/latex] <span style="margin-left:20px">Initialize input and [latex]alpha](https://s0.wp.com/latex.php?latex=%5Ctext%7Bwhile%7D+%28%28%5Cexists+x+%5Cin+%5Calpha+%7C+x+%3D+0+%29+%5Ctext%7B+%7D+%5C%26+%5C%26+%5Ctext%7B+%7D+%28%5Ctext%7Bcounter%7D+%3C+%5Ctext%7Bmax%5C_iter%7D%29%29%26%2391%3B%2Flatex%26%2393%3B+%3Cspan+style%3D%22margin-left%3A20px%22%3EInitialize+input+and+%5Blatex%5Dalpha&bg=ffffff&fg=000&s=0&c=20201002)


Calculate 
Save old 
Compute 

Continue to
Compute 
Continue to
Compute and clip new value for
Determine value for
Compute 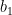
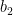
Compute 






![\text{if } (| \alpha_j - \alpha_j^{(old)} < 10^{-5})[/latex] <b>(*A*)</b></span><br /> <span style="margin-left:100px">Continue to [latex]\text{next j}](https://s0.wp.com/latex.php?latex=%5Ctext%7Bif+%7D+%28%7C+%5Calpha_j+-+%5Calpha_j%5E%7B%28old%29%7D+%3C+10%5E%7B-5%7D%29%26%2391%3B%2Flatex%26%2393%3B+%3Cb%3E%28%2AA%2A%29%3C%2Fb%3E%3C%2Fspan%3E%3Cbr+%2F%3E+%3Cspan+style%3D%22margin-left%3A100px%22%3EContinue+to+%5Blatex%5D%5Ctext%7Bnext+j%7D&bg=ffffff&fg=000&s=0&c=20201002)




Algorithm Legend
(*A*): If the difference between the new 
(*B*): Useful data are those samples whose
(2):
(10):
(11):
(12):
(14):
(15): ![\alpha_j := \begin{cases} H \quad \text{if } \alpha_j > H \\<br /> \alpha_j \quad \text{if } L \leq \alpha_j \leq H \\<br /> L \quad \text{if } \alpha_j < L \end{cases}[/latex] (16): [latex]\alpha_i := \alpha_i + y^{(i)} y^{(j)} (\alpha_j^{(old)} - \alpha_j)[/latex] (17): [latex]b_1 = b - E_i - y^{(i)} (\alpha_i^{(old)} - \alpha_i) \langle x^{(i)},x^{(i)} \rangle - y^{(j)} (\alpha_j^{(old)} - \alpha_j) \langle x^{(i)},x^{(j)} \rangle[/latex] (18): [latex]b_2 = b - E_j - y^{(i)} (\alpha_i^{(old)} - \alpha_i) \langle x^{(i)},x^{(j)} \rangle - y^{(j)} (\alpha_j^{(old)} - \alpha_j) \langle x^{(j)},x^{(j)} \rangle[/latex] (19): [latex]\alpha_j := \begin{cases} b_1 \quad \quad \text{if } 0 < \alpha_i < C \\ b_2 \quad \quad \text{if } 0 < \alpha_j < C \\ (b_1 + b_2)/2 \quad \text{otherwise} \end{cases}[/latex] <h4>Source Code Legend</h4> <p>(*1*): This error function arises when we try to see the difference between our output and the target: [latex]E_i = f(x_i) - y_i = \overrightarrow{w}^T \overrightarrow{x_i}](https://s0.wp.com/latex.php?latex=%5Calpha_j+%3A%3D+%5Cbegin%7Bcases%7D+H+%5Cquad+%5Ctext%7Bif+%7D+%5Calpha_j+%3E+H+%5C%5C%3Cbr+%2F%3E+%5Calpha_j+%5Cquad+%5Ctext%7Bif+%7D+L+%5Cleq+%5Calpha_j+%5Cleq+H+%5C%5C%3Cbr+%2F%3E+L+%5Cquad+%5Ctext%7Bif+%7D+%5Calpha_j+%3C+L+%5Cend%7Bcases%7D%26%2391%3B%2Flatex%26%2393%3B+%2816%29%3A+%26%2391%3Blatex%26%2393%3B%5Calpha_i+%3A%3D+%5Calpha_i+%2B+y%5E%7B%28i%29%7D+y%5E%7B%28j%29%7D+%28%5Calpha_j%5E%7B%28old%29%7D+-+%5Calpha_j%29%26%2391%3B%2Flatex%26%2393%3B+%2817%29%3A+%26%2391%3Blatex%26%2393%3Bb_1+%3D+b+-+E_i+-+y%5E%7B%28i%29%7D+%28%5Calpha_i%5E%7B%28old%29%7D+-+%5Calpha_i%29+%5Clangle+x%5E%7B%28i%29%7D%2Cx%5E%7B%28i%29%7D+%5Crangle+-+y%5E%7B%28j%29%7D+%28%5Calpha_j%5E%7B%28old%29%7D+-+%5Calpha_j%29+%5Clangle+x%5E%7B%28i%29%7D%2Cx%5E%7B%28j%29%7D+%5Crangle%26%2391%3B%2Flatex%26%2393%3B+%2818%29%3A+%26%2391%3Blatex%26%2393%3Bb_2+%3D+b+-+E_j+-+y%5E%7B%28i%29%7D+%28%5Calpha_i%5E%7B%28old%29%7D+-+%5Calpha_i%29+%5Clangle+x%5E%7B%28i%29%7D%2Cx%5E%7B%28j%29%7D+%5Crangle+-+y%5E%7B%28j%29%7D+%28%5Calpha_j%5E%7B%28old%29%7D+-+%5Calpha_j%29+%5Clangle+x%5E%7B%28j%29%7D%2Cx%5E%7B%28j%29%7D+%5Crangle%26%2391%3B%2Flatex%26%2393%3B+%2819%29%3A+%26%2391%3Blatex%26%2393%3B%5Calpha_j+%3A%3D+%5Cbegin%7Bcases%7D+b_1+%5Cquad+%5Cquad+%5Ctext%7Bif+%7D+0+%3C+%5Calpha_i+%3C+C+%5C%5C+b_2+%5Cquad+%5Cquad+%5Ctext%7Bif+%7D+0+%3C+%5Calpha_j+%3C+C++%5C%5C+%28b_1+%2B+b_2%29%2F2+%5Cquad+%5Ctext%7Botherwise%7D+%5Cend%7Bcases%7D%26%2391%3B%2Flatex%26%2393%3B++++%3Ch4%3ESource+Code+Legend%3C%2Fh4%3E+%3Cp%3E%28%2A1%2A%29%3A+This+error+function+arises+when+we+try+to+see+the+difference+between+our+output+and+the+target%3A+%5Blatex%5DE_i+%3D+f%28x_i%29+-+y_i+%3D+%5Coverrightarrow%7Bw%7D%5ET+%5Coverrightarrow%7Bx_i%7D&bg=ffffff&fg=000&s=0&c=20201002)

(*2*): This line has 4 parts: if ((a && b) || (c && d)). A and C parts control that you will not enter if the error is lower than the tolerance. And honestly, I don't get parts B and D. Actually I tried to run this code with several problems and the result is always the same with and without those parts. I know that alpha is constrained to be within that range, but I don't see the relationship between A and B parts, and C and D parts separately, because that double constraint (be greater than 0 and lower than C) should be always checked.






Results
Given a 3D space we have two samples from each class. The last column indicates the class:

Solution:
![W = [0.3333 0 -0.3333] \to f(x,y,z) = x-z](https://s0.wp.com/latex.php?latex=W+%3D+%5B0.3333+0+-0.3333%5D+%5Cto+f%28x%2Cy%2Cz%29+%3D+x-z&bg=ffffff&fg=000&s=0&c=20201002)
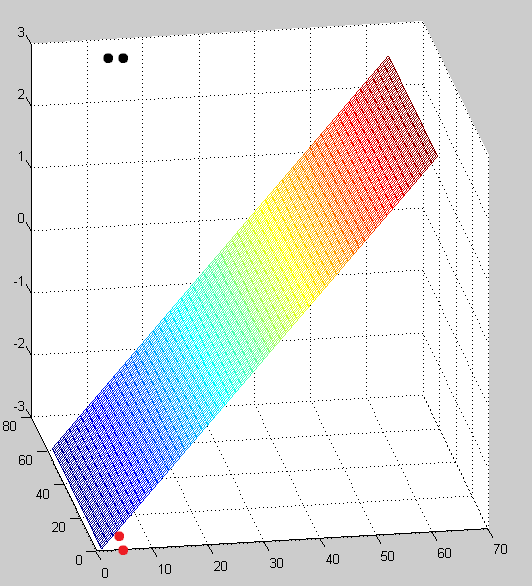
The code is provided in the Source code section.
References
1. The Simplified SMO Algorithm http://cs229.stanford.edu/materials/smo.pdf
2. Sequential Minimal Optimization for SVM http://www.cs.iastate.edu/~honavar/smo-svm.pdf
3. Inequality-constrained Quadratic Programming - Example https://www.youtube.com/watch?v=e6jDGxNZ-kk
I would like to modify the parallel sequential minimal optimization algorithm for my thesis and need some help. Based on recommendations for future work, the authors suggested that it is worthy to perform the multiclass classification problem in parallel…can you help me with some explanation? Tks