After reading some chapters related to reinforcement learning and some minutes spent watching videos in Youtube about fancy RL robots, I decided to put it into practice. This is the first algorithm I design, so I wanted to keep it simple. Probably I will add later more interesting features and challenges, so this video could be the first of a series of goalkeeper simulations.
It is worth saying that I took the freedom of designing it from scratch, so I haven’t followed any famous efficient algorithm.
The problem
-The ball can come randomly from 3 different heights, so the “player” can move up to 3 different positions. Therefore, I have 9 simple states.
-Goal: catching the ball
Problems I met
The easiest way was designing this problem as a 9 state problems, however I attempted to do it using only 5 states since many of them can be considered the same. However, due to the fact that I cannot simply jump from any of the real 9 states to whichever I want, this assumption is incorrect.
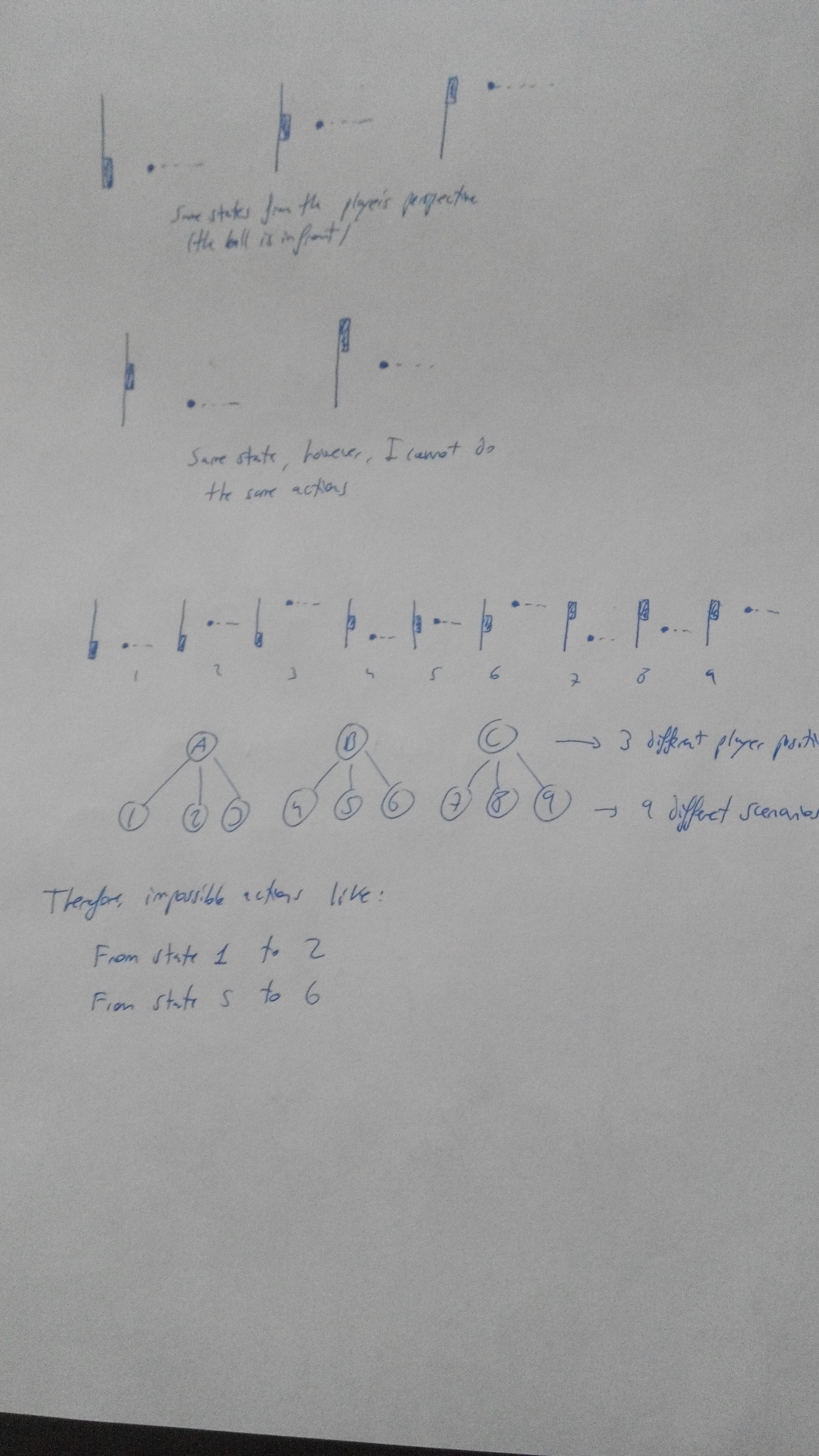
How shall I take into account the fact that I cannot jump to the state I want? Well, I decided to make the algorithm think that doing that action will retrieve a very negative reward. The reward matrix in the beginning looks like this:
-99 2 -99 -99 2 -99 -99 2 -99
-99 -99 2 -99 -99 2 -99 -99 2
2 -99 -99 2 -99 -99 2 -99 -99
-99 2 -99 -99 2 -99 -99 2 -99
-99 -99 2 -99 -99 2 -99 -99 2
2 -99 -99 2 -99 -99 2 -99 -99
-99 2 -99 -99 2 -99 -99 2 -99
-99 -99 2 -99 -99 2 -99 -99 2
Rows represent the current state, and columns the target state, so if the algorithm tries to foresee the reward he thinks he will get when he’s on the state 5 and plans to jump to the state 2, he just needs to retrieve the 5,2 element in the matrix: 2
Why 2? In this algorithm I only have two types of rewards: the good one (+1) and the bad one (-1). After I get a reward, I will update this table, so I will have +1, -1 and -99 entries. If a 2 value remains in the matrix, as it’s the highest value it can has, the algorithm will try to explore that solution (the highest reward is always preferred). I can say that this is a solution based 100% on the exploration part.
States 1, 5 and 9 are the ones which make the algorithm get the highest reward. Considering that from each state I can only do 3 moves (including moving to the same state), there are 3*9=27 possibilities, and for each state there is always one good move, so we have that the maximum errors (scored) are 27-9=18, as we can see in the demonstration.
This is how the reward matrix looks like at the end of the learning:
-99 -1 -99 -99 1 -99 -99 -1 -99
-99 -99 -1 -99 -99 -1 -99 -99 1
1 -99 -99 -1 -99 -99 -1 -99 -99
-99 -1 -99 -99 1 -99 -99 -1 -99
-99 -99 -1 -99 -99 -1 -99 -99 1
1 -99 -99 -1 -99 -99 -1 -99 -99
-99 -1 -99 -99 1 -99 -99 -1 -99
-99 -99 -1 -99 -99 -1 -99 -99 1
Simulation:
Dude can you give the code for it.
You can find the code in here http://laid.delanover.com/source-code/ section “Reinforcement learning”.