Title: Large-batch training for Deep Learning: Generalization gap and Minima
Authors: Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, Ping Tak Peter Tang
Link: https://arxiv.org/abs/1609.04836
Quick summary:
The main goal of this paper is to discuss about the minimizers resulting from using large and small batch size and to provide with a measure of how sharp is the minimum found. Loss functions depend on both the geometry of the cost function and the size and properties of the training set. Using batches have been proven to converge to minimizers and stationary points of strongly-convex functions, avoid saddle-points and robustness to input data, but a large batch size is shown to lead to a loss in generalization performance (generalization gap).
They observe that this loss of generalization is related to the sharpness of the minimizer obtain by large-batch (LB) methods. On the other hand, methods using small batch (SB) lead to flatter minimizers.
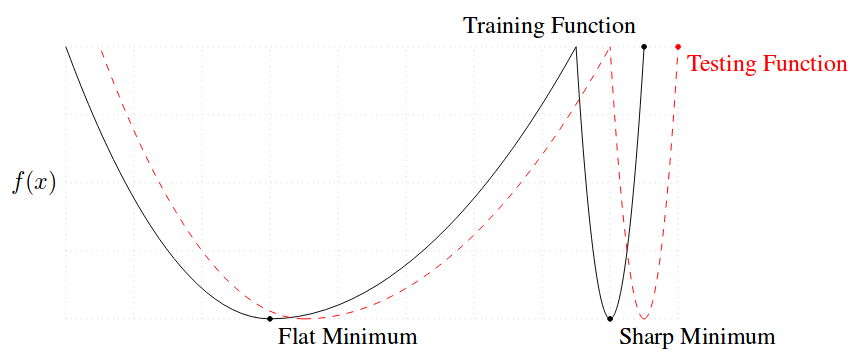
There is a clear trade-off because LB are desirable since they are computationally efficient and less noisy but if they are too large they will not generalize well. They mention some reasons why this might happen: 1) LB methods produce overfitting, 2) they are attracted to saddle points, 3) they lack the exploratory properties SB has, 4) and they tend to zoom-in on the minimizer closest to the initial point. They had a look at the minimizers and realized that sharp minimizers have significantly large positive eigenvalues whereas flat minimizers have small eigenvalues, thus their conclusion is that the sharpness of a minimizer can be characterized by the magnitude of the eigenvalues 
For this reason, they come up with a formula to measure the sharpness of a function, and the results show that it can distinguish quite well how different it is the minimizer when large and small batches are used. This measure is basically based on drawing a small box around the minimizer and check largest value. However, a minimizer does not usually have the shape of a cone. Values at one side can be very large whereas on the other side be flatter.

They try to improve the generalization problem of LB by doing data augmentation, conservative training and adversarial training and although they help to reduce the generalization gap, they do not solve the problem completely. They also experiment combining small and large batches and hypothesize that a gradual increase of the batch size might help the generalization process.
The authors observe that the noisy in the gradient when using SB pushes the iterates out of sharp minimizers, thus encouraging movement towards a flatter minimizer. They also observe that LB methods are usually attracted to minimizers close to the starting point and, in contrast, SB tend to go further away.