This very informal review of the activation function RReLU compares the performance of the same network (with and without batch normalization) using different activation functions: ReLU, LReLU, PReLU, ELU and an less famous RReLU. The difference between them lies on their behavior from ![[- \infty,0]](https://s0.wp.com/latex.php?latex=%5B-+%5Cinfty%2C0%5D&bg=ffffff&fg=000&s=0&c=20201002)
When a negative value arises, ReLU deactivates the neuron by setting a 0 value whereas LReLU, PReLU and RReLU allow a small negative value. In contrast, ELU has a smooth curve around the zero to make it derivable resulting in a more natural gradient and instead of deactivating the neuron negative values are mapped into a negative one. The authors claim that this pushes the mean unit closer to zero, like batch normalization [1].

LReLU, PReLU and RReLU provide with negative values in the negative part of the respective functions. LReLU is using a small tilted slope whereas PReLU learns the steepness of this slope. On the other hand, RReLU, the function we will study here, sets this slope to be a random value between an upper and lower bound during the training and an average of these bounds during the testing. The authors of the original paper get their inspiration from Kaggle competition and even use the same values [2]. These are random values between 3 and 8 during the training and a fixed value 5.5 during testing.
Notice that in [2] and consequently in the following tests, the variable 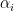


Results
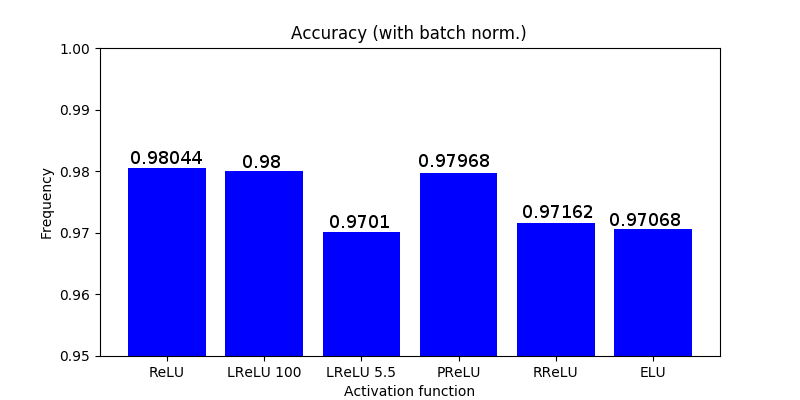
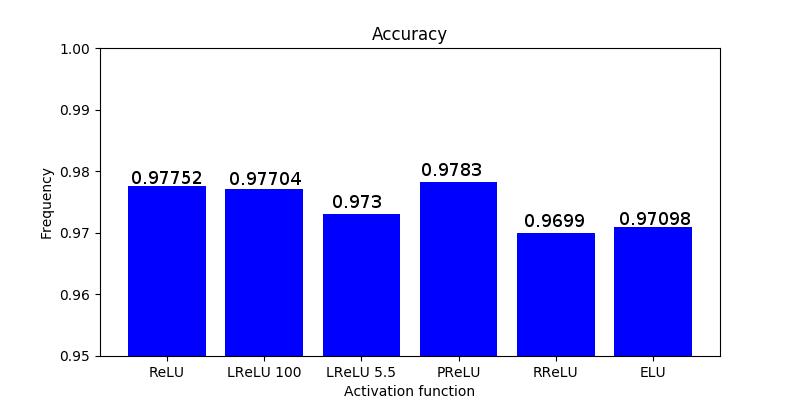
As in the paper where RReLU is introduced, I used the same activation function configurations plus ELU (default configuration). I run a very simple neural network using MNIST dataset with and without batch normalization and as we can see in the figure below RReLU does not only perform among the words but the simple ReLU performs the best when normalization is used and almost the best when no normalization is added.
Notes on Tensorflow
This activation function requires to constantly use new random values that need to be initalized constantly while the network is training. As we can see in the corresponding tutorial video and the source code the initializer needs to be called on each iteration during the training by:
The code is provided in the Source code section.
References
1. Clevert D.A., Unterthiner T. and Hochreiter S. 2016. Fast and accurate Deep Network Learning by Exponential Linear Units (ELUs). ICLR 2016.
2. Xu B., Wang N., Chen T. and Li M. 2015. Empirical Evaluation of Rectified Activations in Convolutional Network.