Brief Introduction
Line detection is one of the most important and basic feature extraction methods. Many currently developing and promising fields such as self driving cars may use line detection to detect lanes. Thus, it is important to understand how it works (both mathematically and the implementation).

As we are using a 2D plane (an image) we can use Cartesian or Polar parameterization. Polar parameterization is useful not only because of its own advantages, but also because it allows the algorithm to reduce costs by space reduction.
Cartesian
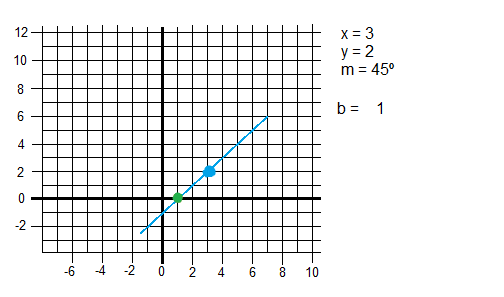
Let us keep in mind the line equation:
[latex]y = mx + c[/latex]
In homogeneous form:
[latex]Ay+Bx +1 = 0 \quad[/latex] where [latex]A = -1/c, B = m/c[/latex]
To determine the line we must find [latex]m, c \quad \text{(or A, B)}[/latex]
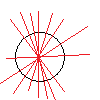
The way HT works is by simply counting the potential solution in an accumulator, tracing all possible lines for each point within the main iteration. Hence, finding the maximum in the accumulator means finding the line with the highest probability.
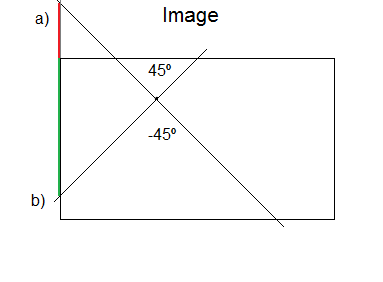
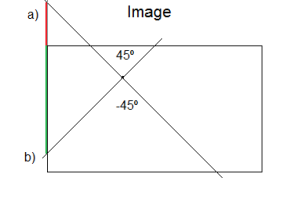
When iterating, after checking that a black pixel (typically corresponding to an edge) has been detected, it iterates over two different “for” loops. The first loop corresponds to angles between -45 and 45 degrees (both inclusive) and the second loop between 45 and 135. It is necessary to separate them because for slopes whose degrees are larger than 45 or lower than -45, [latex]c[/latex] (intersection with y-axis) may take large values. Thus, an additional accumulator for angles between 45 and 135 is needed, which will store a similar [latex]c[/latex] variable whose value is the intersection with x-axis rather than y-axis.
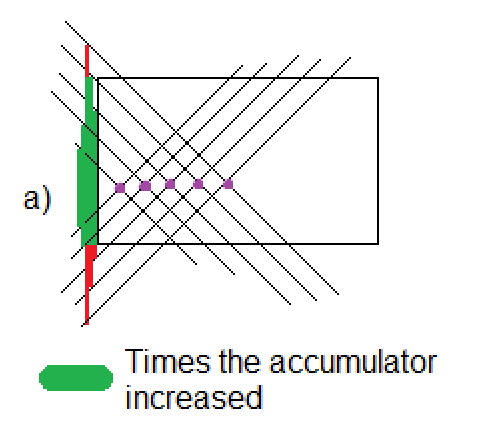
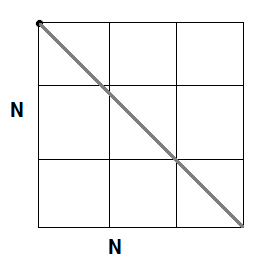
As we can see in the image below for the case when angles are between -45 and 45, when [latex]c[/latex] is out of bounds (a) (bounds are 0 and the height), the accumulator is not increased. Otherwise, the accumulator will increase for all those angles between the allowed boundaries (b) (green). Note that all those angles that are outside are later taken into account when examining x-axis.
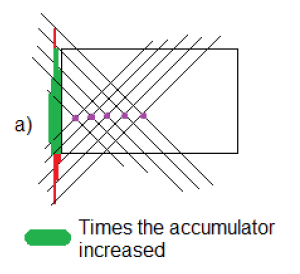
In the following picture, we have 5 points that may compound a line. In the green zone of the left side you can see how the region in the middle is getting larger and larger. That represents the accumulator values for those angles and intersection with the y-axis, and it shows that there is a high probability to find a line, as it is. Likewise, we can also see that the behavior of this algorithm is strong against noise and occlusion. As a drawback, two large matrices are needed.
Cartesian Algorithm
Iterate over rows (y)
Iterate over columns(x)
If an edge is detected
For angles between -45 and 45 (m)
Calculate c (y-axis intersections)
If c is between the bounds, increase accumulatorA
For angles between 45 and 135 (m)
Calculate c (x-axis intersections)
If c is between the bounds, increase accumulatorB
Cartesian Examples
Correction
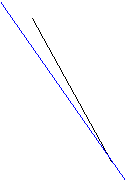
The previous algorithm taken from [1] was used to understand Hough Transform for Cartesian coordinate systems, however, this algorithm failed to classify some lines such as the following:

At first I thought that the problem could be my implementation of how to draw those lines given the accumulators, but after a deep study of the algorithm I realized what was the mistake. In addition to the author mistake, I added a small improvement that may help to understand HT in Cartesian coordinate systems.
First of all, in the author’s algorithm the accumulators are split depending on the degrees that are being examined. The first accumulator stores vertical intersections of the y-axis on angles between -45 and 45 whereas the second is responsible of the x-axis intersections on angles between 45 and 135.
If a nearly horizontal line is examined, the first accumulator (vertical intersections) will have a higher maxima than the second accumulator. This can be seen in the image above the algorithm: in the vertical accumulator a peak around the center will be created. In contrast, the horizontal accumulator will grow but very plain. Let us recall that in the accumulator there are represented the pixel where the line should start (the intersection with the axis) and the angle. Once this is completely understood, one can imagine many problematic scenarios such as the one depicted previously.
In the previous image, the line that should be generated must start in the x-axis. This means that the horizontal accumulator (the second) should have a higher peak than the vertical one. However, the angle corresponding to that line is between -45 and 45 degrees, so it is only examined by the first accumulator. Thus, the assumption that one accumulator should be in charge of a certain range of degrees while the second takes cares of the rest, is extremely naïve. The solution to this problem is by simply computing the range from -45 to 135 degrees in both accumulators. It is worth saying that the computation time is almost not affected at all, but we need a higher amount of memory.
The improvement to better understand the algorithm is more related with the later line drawing. As the “for” loops and pixel detection works, the image is examined from top to bottom and left to right. This makes our coordinates system move from the typical 0,0 starting in the bottom-left corner to the top-left corner. This shift arises problematic issues regarding the formulas, especially with the one used for the second accumulator (x-axis crossings detection). The formula used for detecting these crossings is:
[latex size=”1.5″]b = \text{round(} x- \frac{y}{\tan{m* \pi / 180}} \text{)}[/latex]
Where [latex]m[/latex] represents the angle and [latex]x, y[/latex] represent the coordinates. This formula may work when the 0,0 is in the bottom-left corner:
But if the coordinate epicenter is moved, it will not work anymore. For this reason, instead of computing [latex]y[/latex] when [latex]b[/latex] is calculated, I decided to compute [latex]yInv = rows – y[/latex]. An alternative solution would be changing the formula.
Final algorithm:
Iterate over rows (y)
Iterate over columns(x)
If an edge is detected
For angles between -45 and 135 (m)
Calculate yInv ([latex]yInv = rows – y[/latex])
Calculate c (y-axis intersections)
If c is between the bounds, increase accumulatorA
Calculate c (x-axis intersections)
If c is between the bounds, increase accumulatorB
Both algorithms (the original and the improved one) are in the Source code section.
Polar
Polar coordinate system is an alternative to the Cartesian in which a radius and angle are needed to locate a single point, rather than X-Y coordinates. The maximum length of the radius can be obtain by the Pythagoras formula: [latex]\sqrt{2} N[/latex] where N is the largest size (width or height).
In contrast with Cartesian, in the Polar algorithm we only need one accumulator. The first dimension of the matrix is the radius which is between 0 and [latex]\sqrt{2} N[/latex], and the second dimension is the angle (0-180). It will work in the same way as Cartesian: examining each point of the edge individually the accumulator will increase in those points which may generate the objective line. The final line will be drawn by finding the maximum value in the accumulator and using the radius and angle where it is located. It may seem a bit confusing how to calculate prospective points in the Polar coordinate system, so I tried to explain it using some drawings.
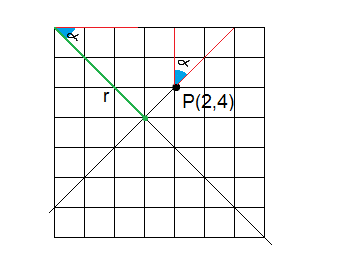
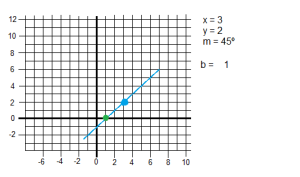
Imagine that we have the point 2,4. It is not difficult to calculate its angle and radius.
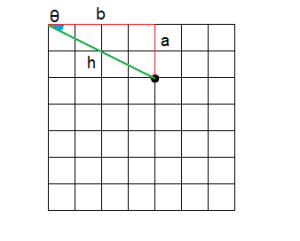
[latex]r = \sqrt{x^2 + y^2} = \sqrt{4^2 + 2^2} = 4.47 \\
\sin{\theta} = \frac{a}{c}; \theta = 26.5[/latex]
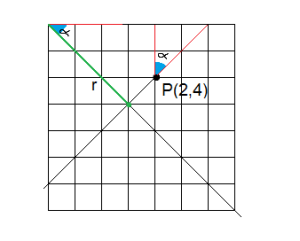
However, for the same point, it looks a bit confusing when examining different angles. This is how it looks when we try to figure out the radius of the same point for a 45º angle.
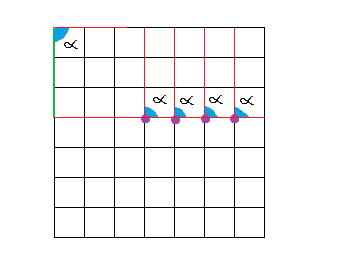
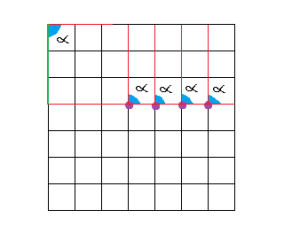
And here is an example of a straight line: 4 purple points in a row. If we examine all the angles, we will realize that for the 90º angle they all reach the same point (3), so the accumulator will be maximum there.
Polar Algorithm
Initialize max value of radius [latex]\sqrt{2} N[/latex]
Iterate over columns (x)
Iterate over rows (y)
If an edge is detected
For angles between 1 and 180 (m)
Calculate the radius (*)
If radius is between the bounds (0 and maximum), increase accumulator
Polar Examples
The same pictures as Cartesian Examples.
Correction
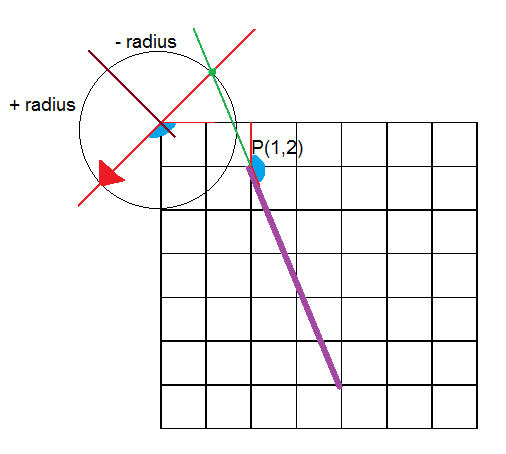
As in the Cartesian algorithm given in [1], in the Polar algorithm another mistake related to the one found in the Cartesian is found as well. This algorithm seems to work always except for one particular case: when one side of the line is bent pointing from top to bottom following a north-west to south-east direction.
Again, the error is to naïvely assume that the previous studied radius-angles were all the possibilities.
The error is illustrated in the picture below. Given that angle (around 150º) the corresponding radius is negative and therefore, it is discarded (radius must be between 0 and [latex]\sqrt{2} N[/latex]). The reason why the radius is negative is very simple: the intersection is in the other side of the line to which it is suppose to intersect (the red line with the arrow). Given this scenario the solution could be a negative radius and 150º degrees or a positive radius but a negative degrees (150-180 = -30º). Both scenarios cannot be stored in the accumulator for obvious reasons. The real (and more expensive in terms of memory) solution would be to extent the accumulator from 1-180 to 1-360 degrees to cover all cases. In this case, this line would be detected in the angle -30+360 = 330º and the radius will be positive because of the orientation of the arrow.
Nonetheless, I tried to study how good or bad was assuming that we only needed to check 1-180 degrees. For this, I run the algorithm through a 150×150 black image to make it fire in every pixel and try each combination. After that, I checked which parts of the accumulator were 0, meaning this that the will never be modified. I did the same in the 1-360 case to see those cases that cannot be seen from the first 1-180º implementation. The black color represents those elements who are never increased whereas the white color represents a zone that can be modified. The width indicates each angle, so in the first case the picture has 180 columns and the second one has 360.
The conclusion drawn from these pictures is that it is possible to make a more efficient algorithm to iterate only over those cases that may be meaningful.
Space Reduction
The space reduction is a modification of the polar algorithm in which the accumulator matrix is reduced from [latex]\text{max},180[/latex] to two matrices: [latex]180,1 \quad \text{and} \quad \text{max},1[/latex]. The huge save is obvious, but again, the naïve approach to enclose the problem from 1 to 180 degrees will have the same consequences as in the previous section.
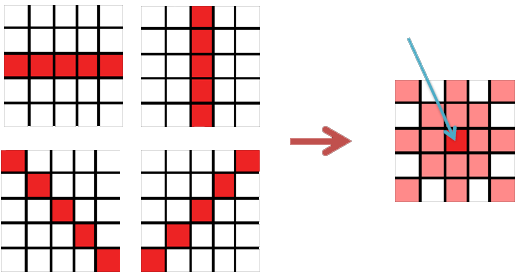
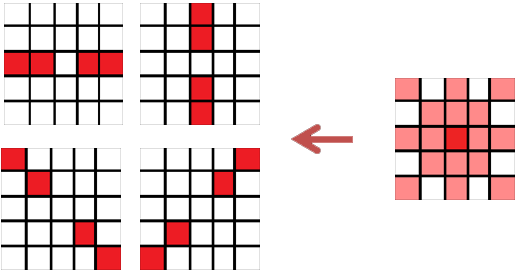
The algorithm presented in the book does not iterate over all angles. Instead, it checks whether a point is located in a certain neighborhood (a 5×5 window) and it calculates the angle for that point.
This approach is more statistical than the previous algorithms, so instead of the accuracy given by knowing the coordinates which correspond to the characteristics of the line, it decides the parameters of the line given the statistics from the accumulator.
The code given in [1], page 211, does not work for almost any line. To make it work, one needs to fix it as in the previous section: adding the 360 degrees.
Additional notes for further improvements
·The accuracy is extremely related with the counter value
·Instead of taking the max, you can take the 2 or 3 max values since more lines may be found.
·Instead of 2 or 3 max, you can establish a threshold
·It can also be possible to study only those lines in a certain region of the picture. For instance, if you want to make a lane recognizer you should focus on the half in the bottom.
The code is provided in the Source code section.
References
1. M. Nixon and A. Aguado. 2008. “First order edge detection operators”, Feature Extraction & Image Processing.