Title: On Calibration of Modern Neural Networks
Authors: Chuan Guo, Geoff Pleiss, Yu Sun, Kilian Q. Weinberger
Link: https://arxiv.org/abs/1706.04599
Quick Summary:
A model is considered calibrated if their confidence levels (probabilities) and their predictions are correlated. For instance, if we predict Y with a confidence level of 0.7, we expect that it will be right the 70% of the times. In contrast, if our model have predictions whose confidence is around 0.9 but they are right only about half of the times (50%) the model is not well calibrated.
The authors describe that recent models are often non-calibrated. The provide some measures to calculate the miscalibration (Expected Calibration Error and Maximum Calibration Error). ECE can be useful in a general application whereas MCE is useful in high-risk applications where we need to be very confident to perform an action (diagnosis prediction). Miscalibration often comes in models with high capacities (deep and wide) and lack of regularization.
There is no correlation between miscalibration and accuracy. They argue that a model can overfit its loss while getting better at predictions. One of their conclusions is “the network learns better classification accuracy at the expense of well-modeled probabilities”.
The authors mention some calibration methods. For binary models: histogram binning, isotonic regression, bayesian binning into quantiles and platt scaling. For multiclass models: extension of binning methods, matrix and vector scaling and temperature scaling. The one who seems to work better is “temperature scaling”.
Temperature scaling can soften the softmax, so if we do 
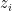
The authors conclude with “modern neural networks exhibit a strange phenomenon: probabilistic error and miscalibration worsen even as classification error is reduced”.