Expectation Maximization (EM) is a classical algorithm in ML for data clustering. Its theoretical background is based on Bayes theorem and although it’s quite straightforward to follow it might be a bit confusing to implement it in more than 1 dimension.
If you want to understand more about EM I recommend you to check out this and this videos.
EM in a nutshell:
- Randomly initialize a mean and variance per class.
- Calculate the probability of each data point to belong to those distributions.
- Calculate the mean and variance based on those probabilities.
- Go to 2. and repeat until convergence.
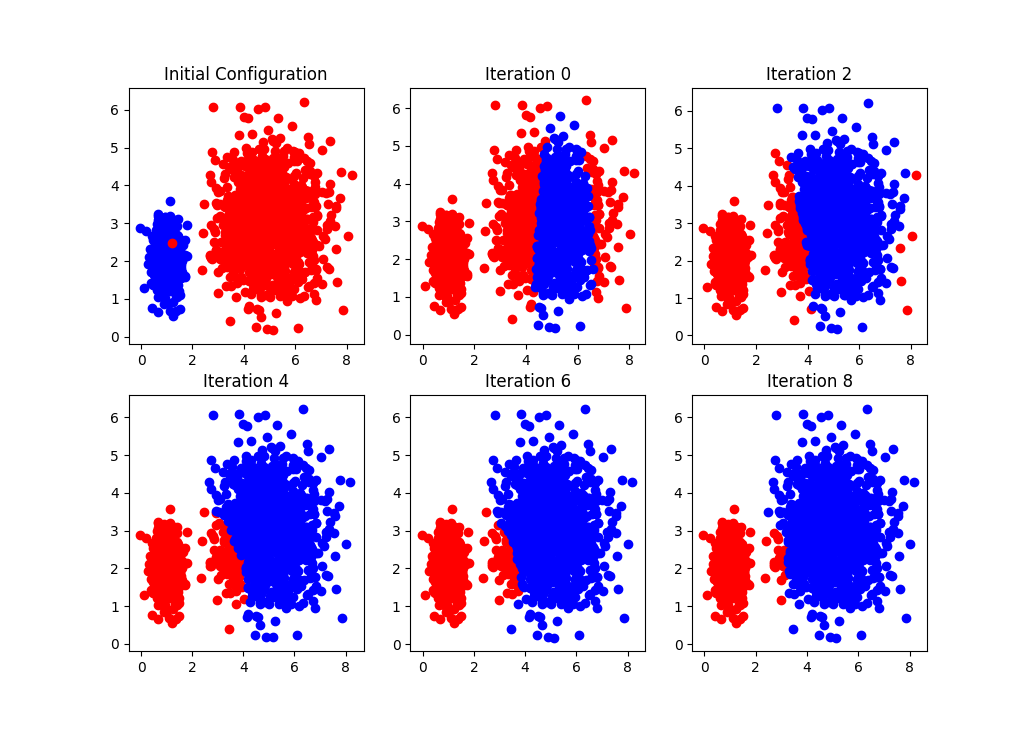
In the Figure above we can see the initial clusters (top-left), and how the classification is changing in different iterations.
This method considerably relies on the mean and variance initialization. An unlucky initialization will provide with a deficient segmentation.
The code is provided in the Source code section.