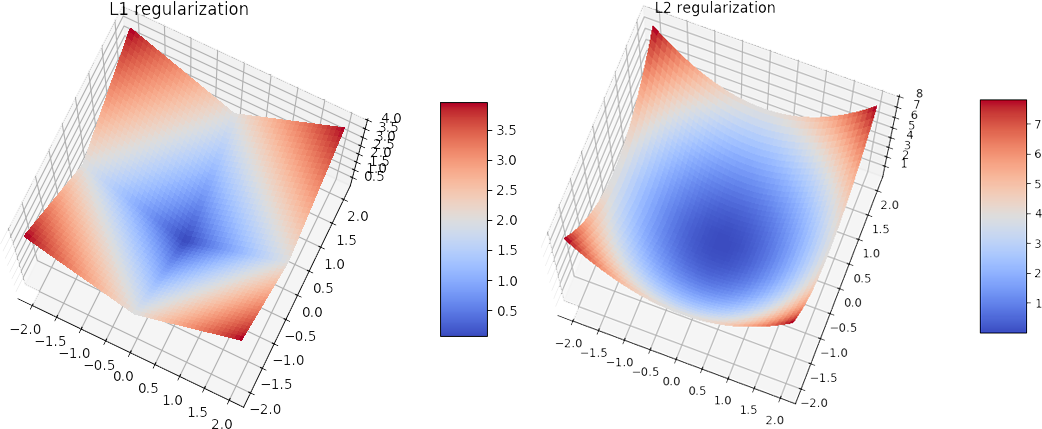
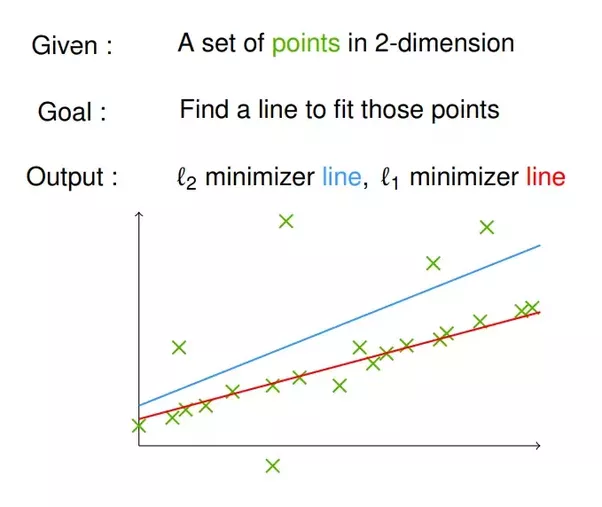
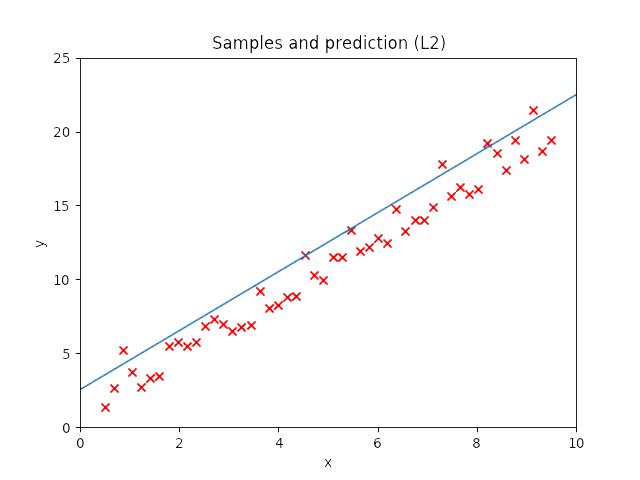
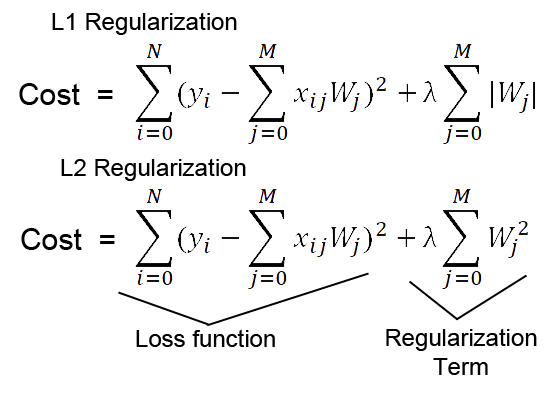Introduction
The goal of this entry is to learn about activation maximization and to prove two basic well-known facts about Deep Learning.
- The way a NN learns the representation of something does not neet to be in a significant way for humans. In fact, most of the times it’s not.
- The found minima depends (among other factors) on the initial state.
It might be interesting to have a look at the representation the NN creates of a object (in case of classification) in order to understand why it is [not] performing well. To make it simple, I used MNIST dataset to create a NN capable of recognizing 0-9 digits. If we think of how does a 1 need to look like so that a person can understand it is a 1, we may think of it as a vertical straight line that can be a bit tilt.
Activation Maximization
Activation maximization, as the name indicates, aims to maximize the activation of certain neurons. Imagine you are training your model with a single image several times. Training is changing the weights accordingly to achieve the lowest loss possible, so the input and the desired output will be constant whereas the weights will be modified iteratively until we reach a minima (or until we decide to stop training). In Activation Maximization, we will keep the weights and the desired output constant and we will modify the input such that it maximizes certain neurons.
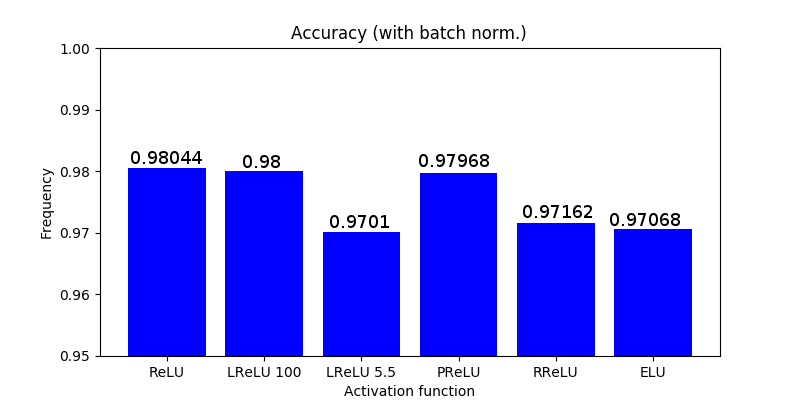
I coded the following simple network in Tensorflow, trained it on MNIST dataset and achieved a 0.984 accuracy:
- 2DConv [3,3,1,32]
- 2DConv [3,3,32,64]
- Max pooling
- Reshape to 12*12*64 = 9216
- Dense 1,9216
- Dense 9216,10
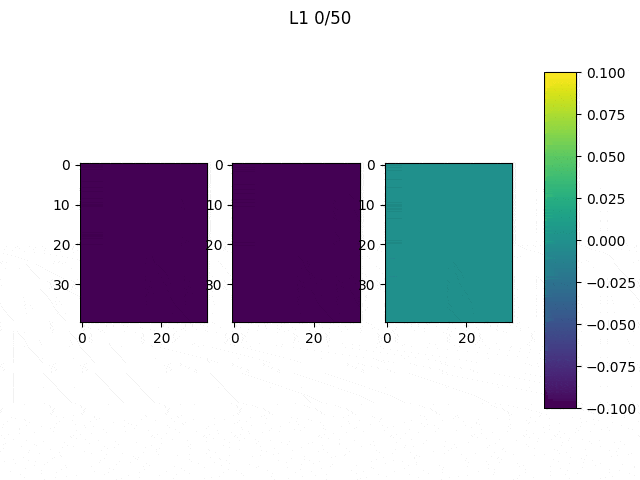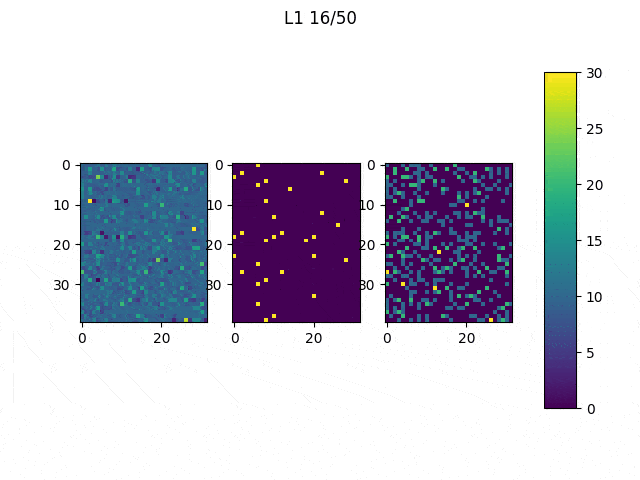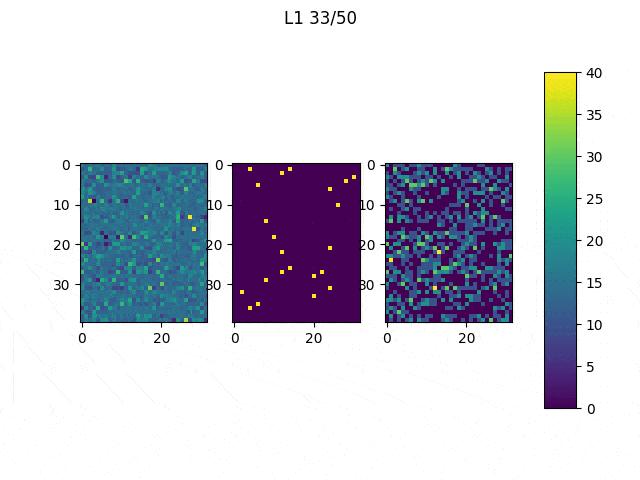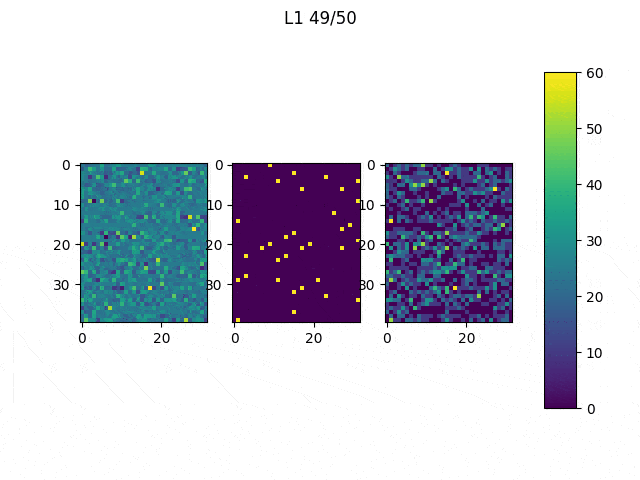
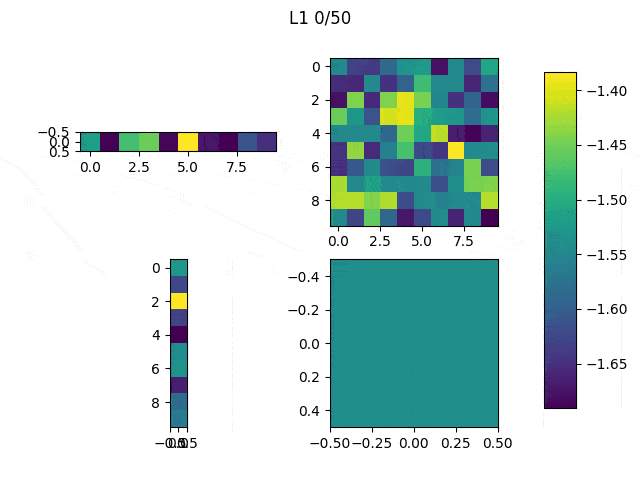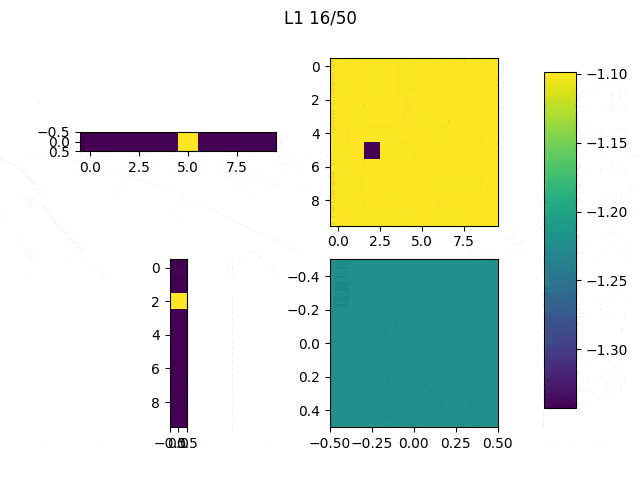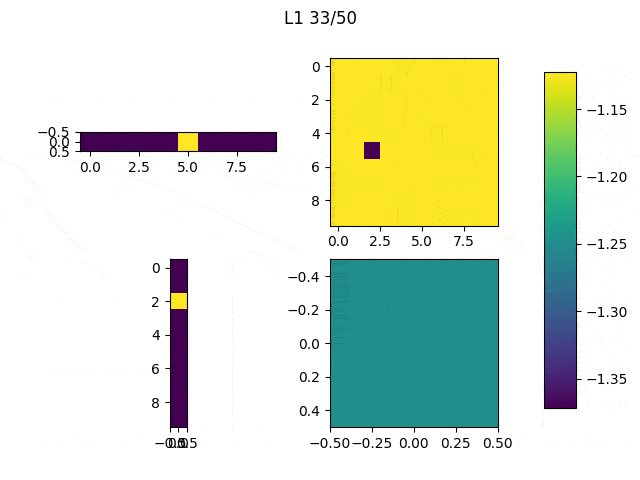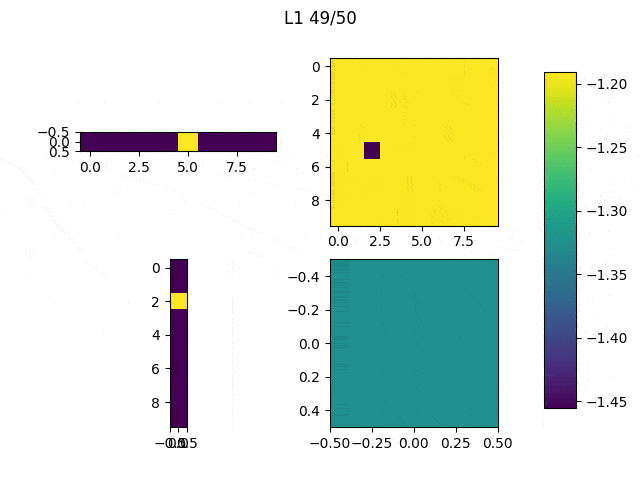
After this, the code was changed to only modify the network’s input and iterate 10 times (Note: the input did not significantly improved much after 10 iterations). The achieved result varies depending on the initial values of the input, as shown in the Table below.
 |
 |
 |
 |
Table 1: The initial values to generate those images were the following: (first row, from left to right) ones, 0.5, (second row, from left to right) zeros and random
Although it may be difficult to see we can quickly understand that depending on the initial values our results will be significantly different, thus it is important to think and try different configurations. In spite of the results obtained from the randomly generated initial input, the other three present a similar structure: the center of the images have large values (white) and they are surrounded by negative values. You may have expected to reach results in which you can clearly see an horizontal white line surrounded by black pixels, but this trained network didn’t need that to distinguish between 1 and other classes. As we can see, the values in the center are the most significant.
We may also see something similar in the random example. In this case, we can visualize the variation of the pixels comparing the initial with the final state.
 |
|
 |
It is indeed hard to see. However, if you input the values obtained to generate this image into the classifier, you will get that the network classifies it as 1 with a 0.99999 confidence. For classifying a one, the network might not have to learn much about it.
For this reason, I calculated the maximum variability between the 10 classes pixel-wise among the whole dataset (standard deviation) and concluded that the samples of the number 2 are very different among them. Let us try to see what would happen if we repeat the same experiment from a random initial state to maximize the activation function for a 2.
 |
 |
In this case, it is easier to see the number we want to classify. Again, using these values will provide with a right classification with a confidence of over 0.9999. In order to prove that the outer pixels (the first and last horizontal and vertical rows of pixels) are irrelevant, we can overwrite the values with 0 and still get a confidence of around 0.9989.
The code is provided in the Source code section.