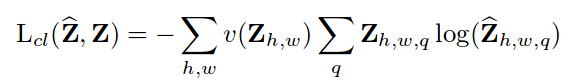Dropout
Dropout [1] is an incredibly popular method to combat overfitting in neural networks. The idea behind Dropout is to approximate an exponential number of models to combine them and predict the output. In machine learning it has been proven the good performance of combining different models to tackle a problem (i.e. AdaBoost), or combining models trained in different parts of the dataset. However, when it comes to deep learning, this becomes too expensive, and Dropout is a technique to approximate this.
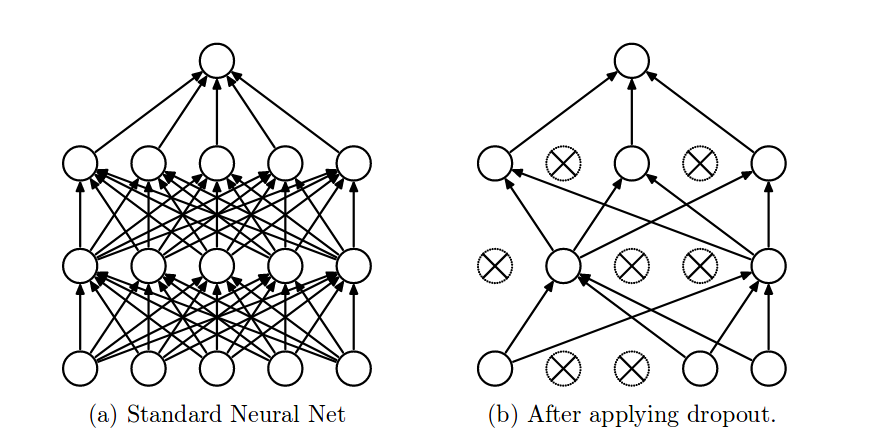
Dropout can be easily implemented by randomly disconnecting some neurons of the network, resulting in what is called a “thinned” network. Thus, if the model has [latex]n[/latex] neurons, there are [latex]2^n[/latex] potential models. Each of them might be trained once or few times, or even not trained at all. Generating one of these random models is done batch-wise so in every batch there will be a new dropout mask (to disconnect the corresponding weights) generated. At train time, each neuron has a probably [latex]p[/latex] of being disconnected. For instance, if [latex]p=0.5[/latex] (recommended configuration, except for the input layer which is recommended to have [latex]p=0.8[/latex]) and we have 200 neurons, the first batch might encounter 90 activated neurons, the second batch might encounter 103 activated neurons, etc.
At test time, all neurons will multiply [latex]p[/latex].

In the image above we can see a simple implementation of a standard feedforward pass: weights multiply inputs, add bias, and pass it to the activation function. The second set of formulas describe how it would look like if we add dropout:
- Generate a dropout mask: Bernoulli random variables (i.e. 1.0*(np.random.random((size))>p)
- Apply the mask to the inputs disconnecting some neurons.
- Use this new layer to multiply weights and add bias
- Finally use the activation function.
All the weights are shared across the potential exponential number of networks, and during backpropagation, only the weights of the “thinned network” will be updated.
How is it implemented in Tensorflow?
In Tensorflow it is implemented in a different way that seems to be equivalent. Let’s have a look at the following example. According to the paper:
Let our neurons be: [latex][1,2,3,4,5,6,7,8][/latex] with [latex]p=0.5[/latex].
At train time, half of the neurons would be randomly disconnected, leading to [latex][1,0,0,4,5,0,7,0][/latex]
At test time, we would have multiplied the whole matrix by p, leading to [latex]0.5*[1,2,3,4,5,6,7,8][/latex]
In other words, we downgrade the outcome at testing time. In contrast, in Tensorflow, we do it the other way around. We increase the values at training time by [latex]1/prob[/latex]. Following our example:
Let our neurons be: [latex][1,2,3,4,5,6,7,8][/latex] with [latex]p=0.5[/latex].
At train time, half of the neurons are randomly disconnected, leading to [latex]1/0.5*[1,0,0,4,5,0,7,0] = [2,0,0,8,5,0,14,0][/latex]
At test time, we would use [latex]p=1[/latex], leading to [latex]1/1*[1,2,3,4,5,6,7,8][/latex]
In other words, at testing time we treat it as a normal neural network without dropout, and at training time we upscale the values by [latex]1/prob[/latex].
The reason why the values are upscale is to preserve the total sum (approx.).
[latex]sum([1,2,3,4,5,6,7,8]) = 36[/latex]
[latex]sum(1/0.5 * [1,0,0,4,5,0,7,0]) = 29[/latex]
This makes sense because if our layer produces certain output, we want to keep it approximately the same regardless of any method we are using to combat overfitting.
Dropout in Tensorflow
Adding a dropout layer in Tensorflow is really easy.
...
W = tf.get_variable("W",shape=[512,128],initializer=init)
b = tf.get_variable("b",initializer=tf.zeros([128]))
dropped = tf.nn.dropout(prev_layer,keep_prob=current_keep_prob)
dense = tf.matmul(dropped,W)+b
act = tf.nn.relu(dense)
...
Where current_keep_prob will be [latex]p[/latex] during training time and 1 during inference/testing time.
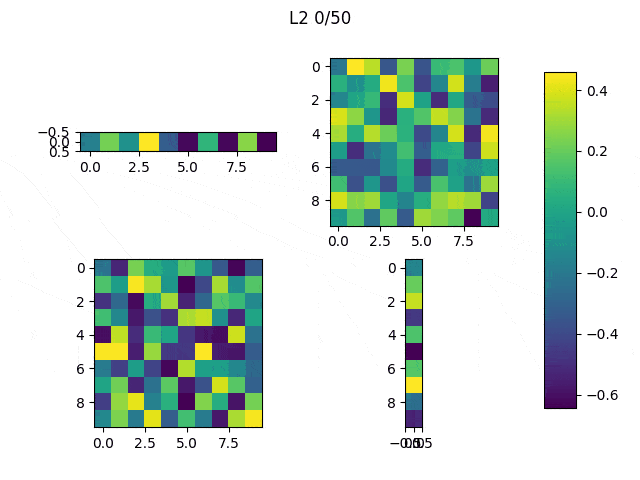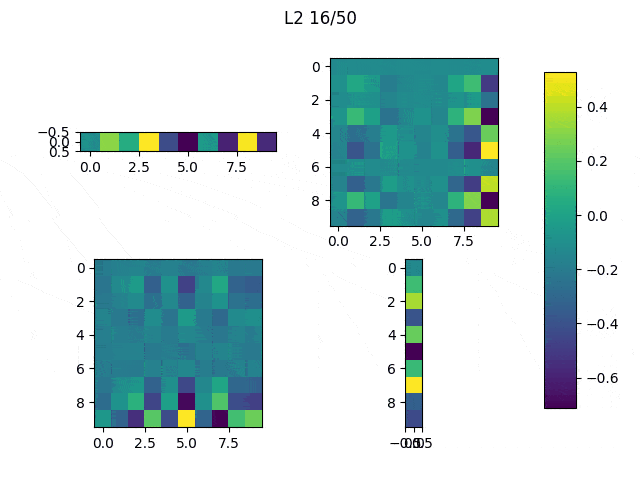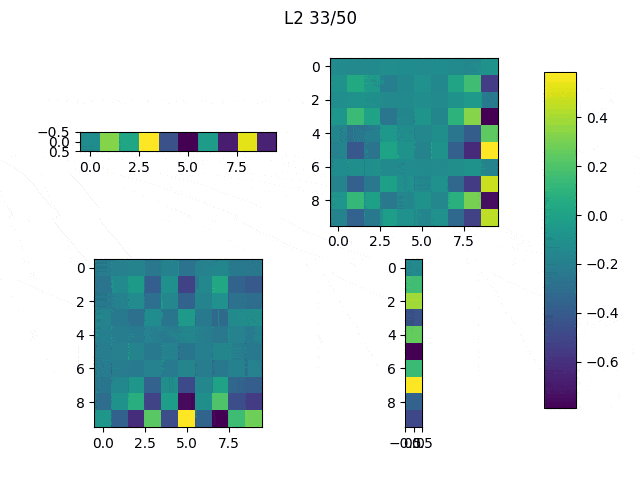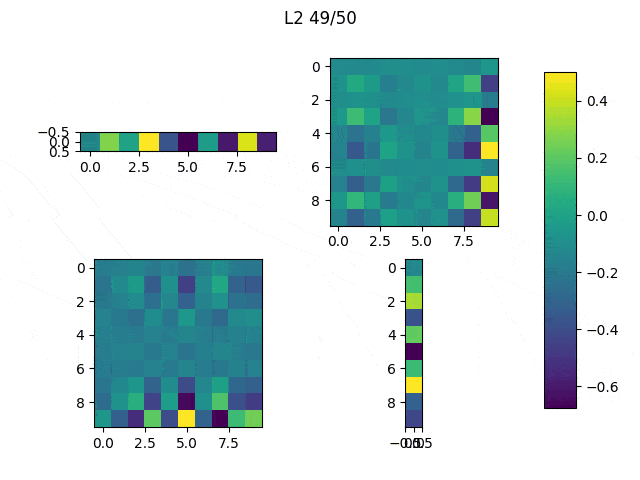
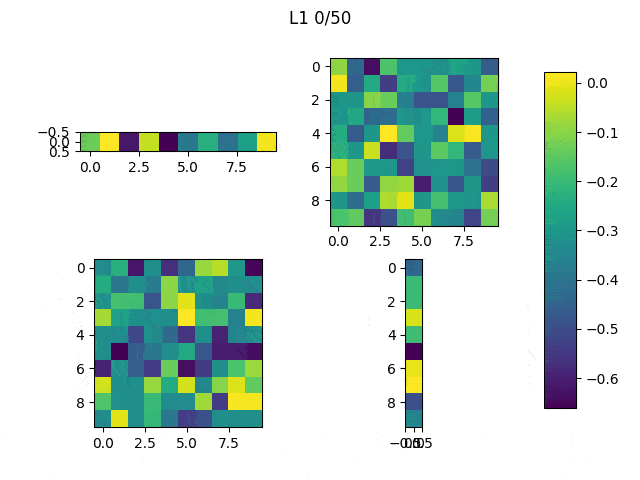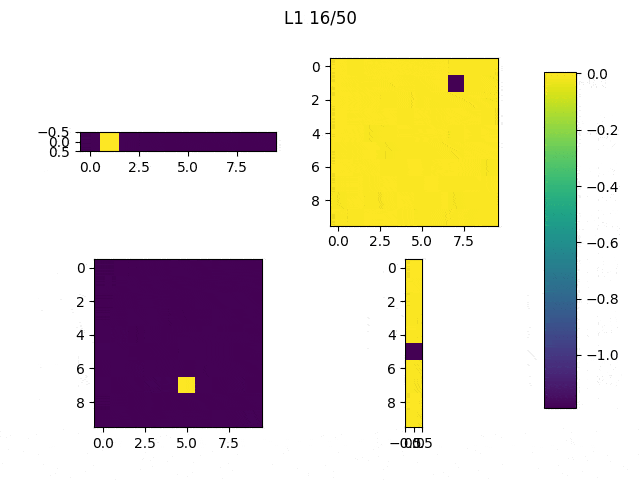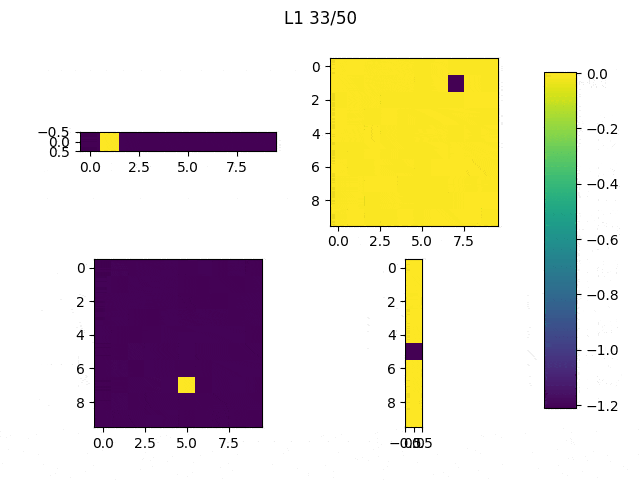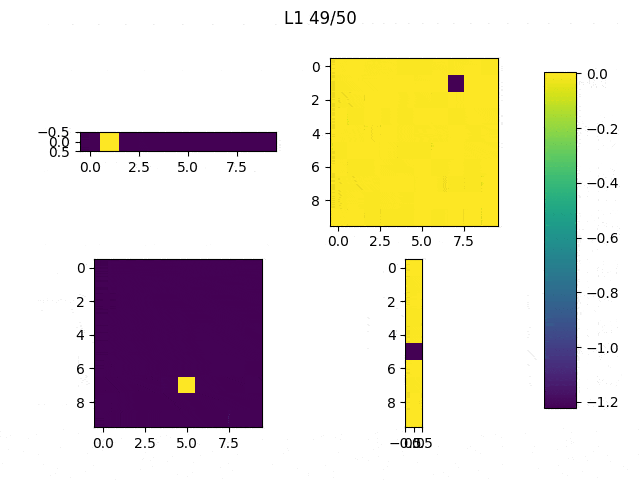
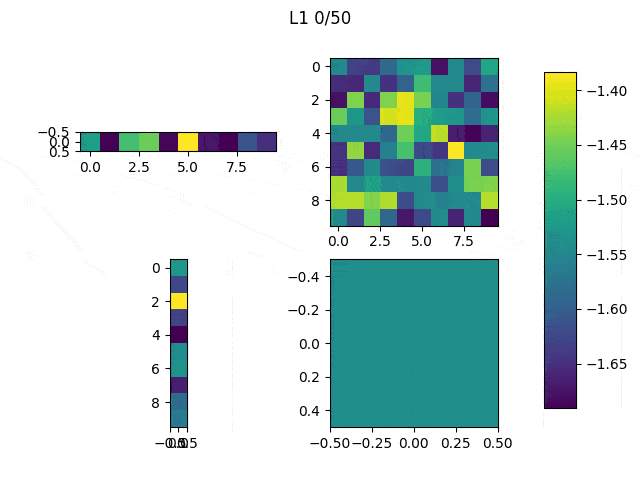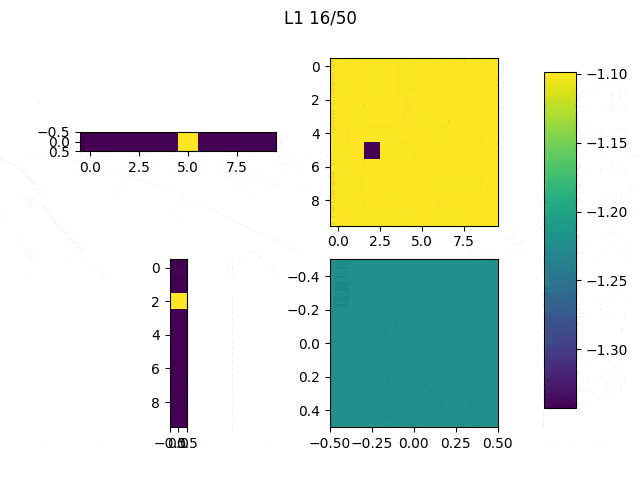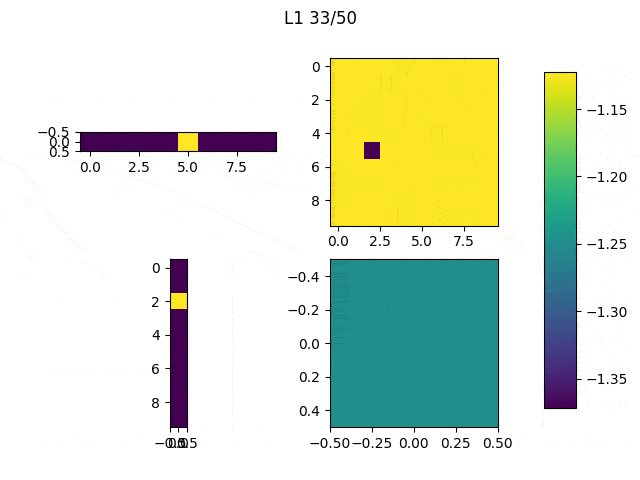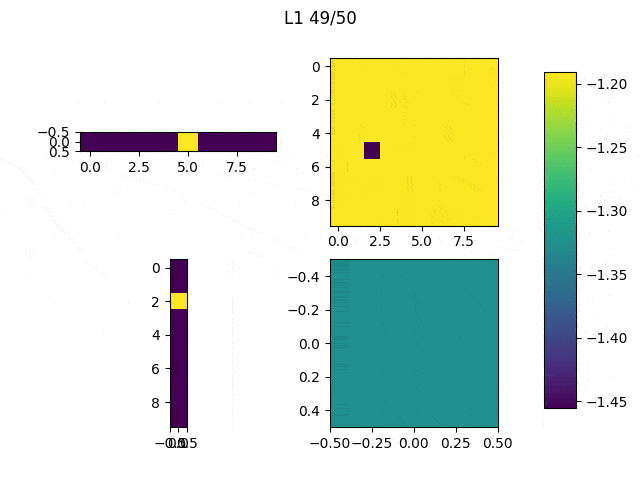
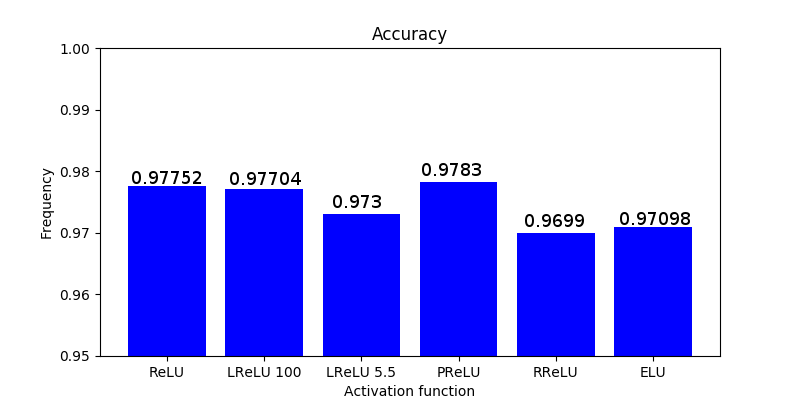
As I mentioned before, only those weights that were successfully masked (without the ones corresponding to the dropped out neurons) will be updated. If I have 100 neurons and [latex]p=0.5[/latex], half of the weights are expected to be updated. In the gif below we can see the evolution of 3 different plots: the first shows how the weights are being updated, the second shows which weights are being updated and the third is a cumulative sum of the second.
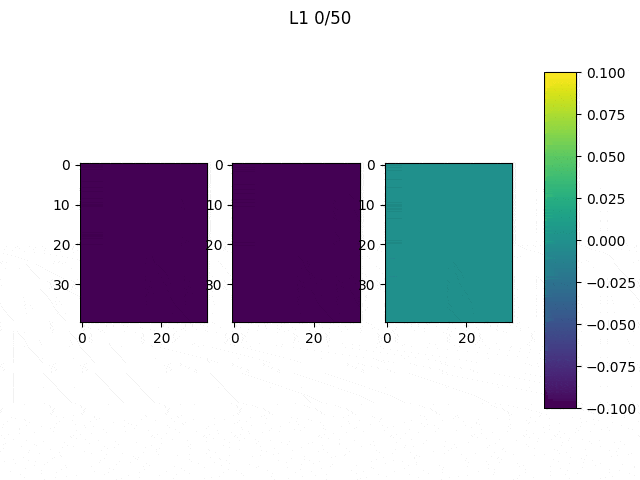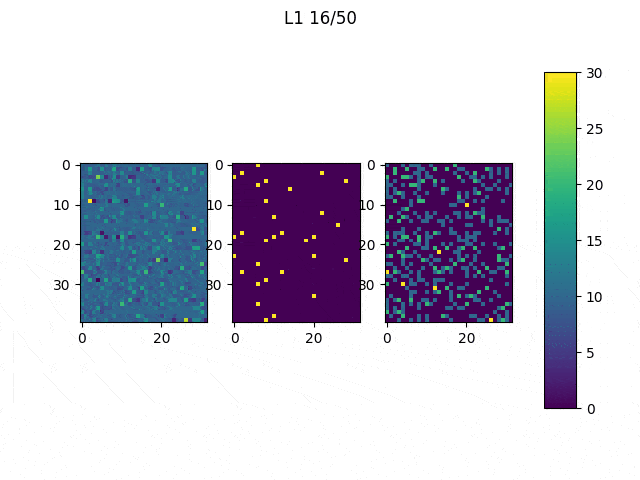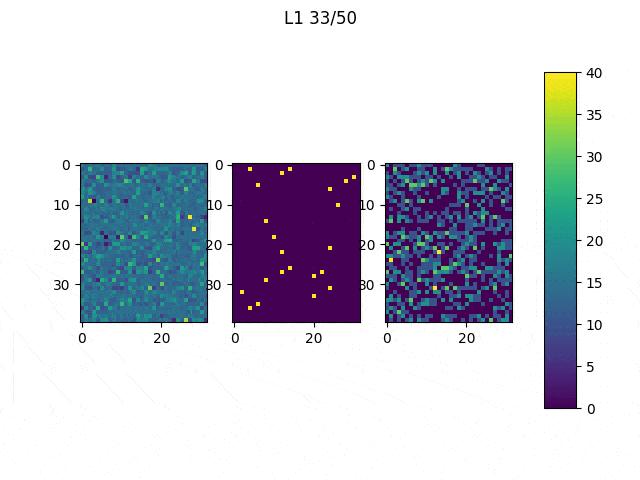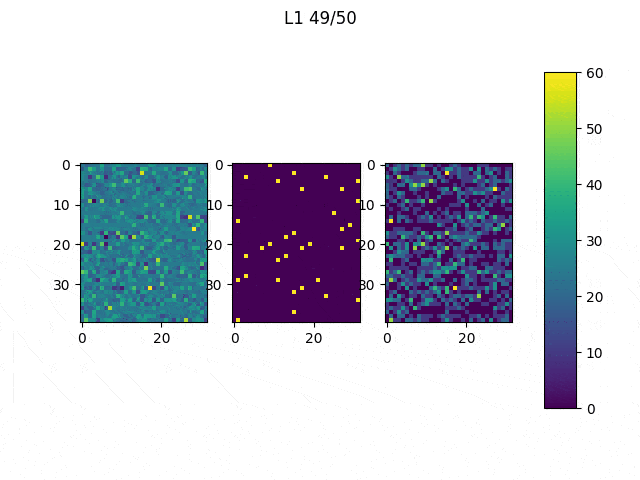
Optimizers comparison with and without Dropout
Due to the nature of AdamOptimizer, it does not follow this rule of updating only the weights belonging to the “thinned” network, so I found interesting to compare the performance of several optimizers in a simple neural network.
Test
Goal: To perform a first step to check the performance between Adam, Adadelta, Adagrad and Gradient Descent across different learning rates (1000 learning rates between 1e-6 to 1e-1).
Dataset: EMNIST (47 classes).
Batch size: 8.
Epochs: 1.
Network: conv2d (3,3,1,32), conv2d (3,3,32,64), max pooling (2,2), reshape (12*12*64), dense (12*12*64,128), dense (128,47).
Weights initialization: he_uniform. Bias initialization: zeros.
Activation layers: ReLU (and softmax at the end of the network).
Cost function: cross entropy.
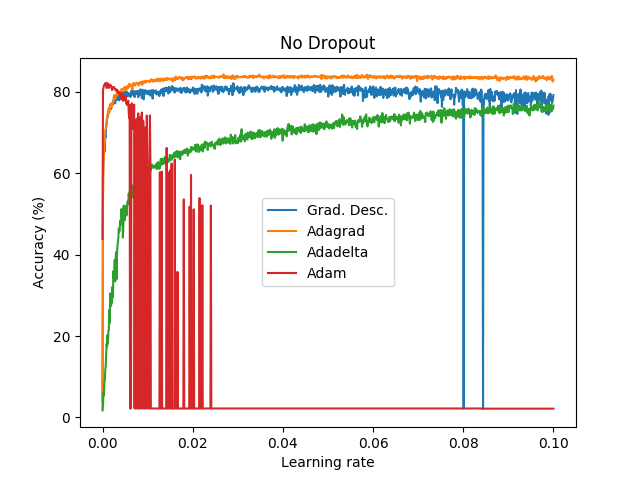
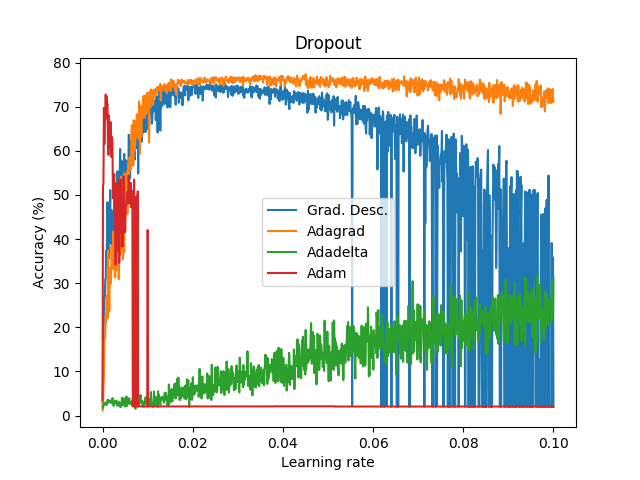
These graph does not show the actual performance of dropout under each optimizer since I only tested a bunch of learning rates without properly examine and focus where it seems to provide good results. In addition, it is not fair to compare on the same learning rates dropout vs non-dropout. Instead, this shows how a first step looks like .
References
1. NNitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov. 2014. “Dropout: A simple way to prevent neural networks from overfitting”