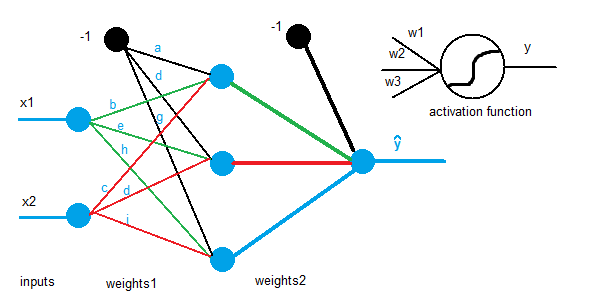
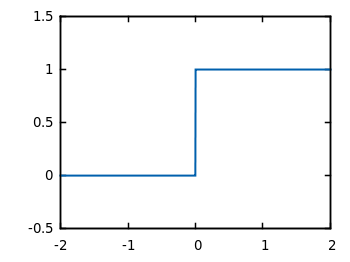
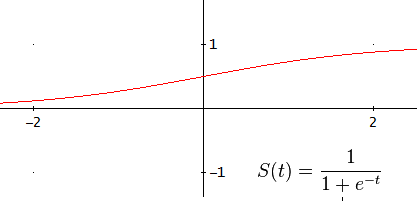Definition
The perceptron is an algorithm for supervised learning of binary classifiers (linear classifier). This algorithm that dates back the late 60s is the most basic form of a neural network. It is important to realize that neural networks algorithms are inspired by neural networks, which does not mean that they entirely function as them.
Perceptrons only have one input and one output layer, so they are mathematically not very complex to understand.

In terms of code, a perceptron is basically a vector of weights which multiplies an input vector and gives an output which is given to a transfer function to determine whether the input belongs to one class or another. Example:
[latex]input = [0.245 \quad 0.942 \quad 0.441] \\
weights = [0.1 \quad 0.32 \quad 0.63 \quad 0.04] \\
sum = -1*0.1 + 0.245*0.1 + 0.942*0.32 + 0.942*0.63 + 0.441*0.04 \\
class = activation(sum) \\[/latex]
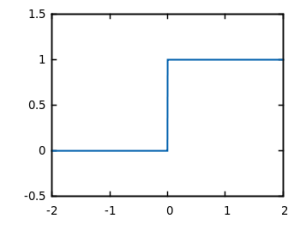
In case of perceptrons, activation function is a simple function which returns 1 if the whole sum is over 0, and return 0 otherwise. This is called step function, because it jumps from 0 to 1 when the input is over 0.

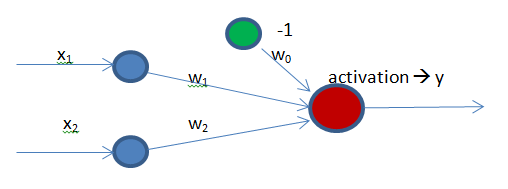
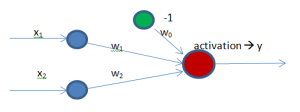
Perceptrons have as many input and output neurons as needed, but they will always have an additional input neuron called bias. The reason why a bias is need is that because without it, the perceptron would not learn about a non-zero input and a zero output or vice versa. When the sum is computed, if all inputs are zero, the result will be therefore zero and the output will inevitably be zero as well. Hence, the weights cannot never learn because the result will always lead to zero.
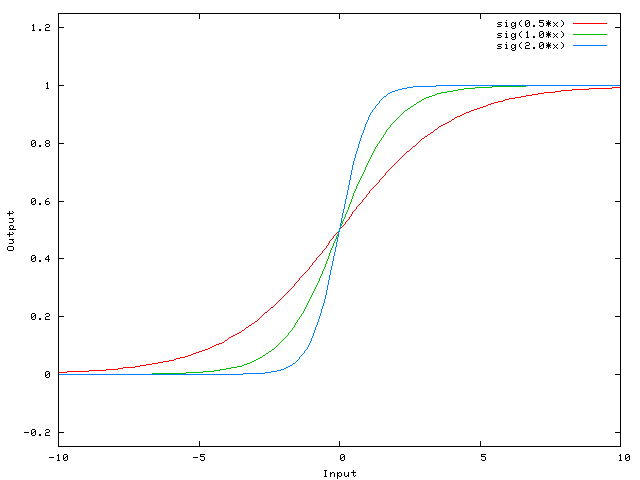
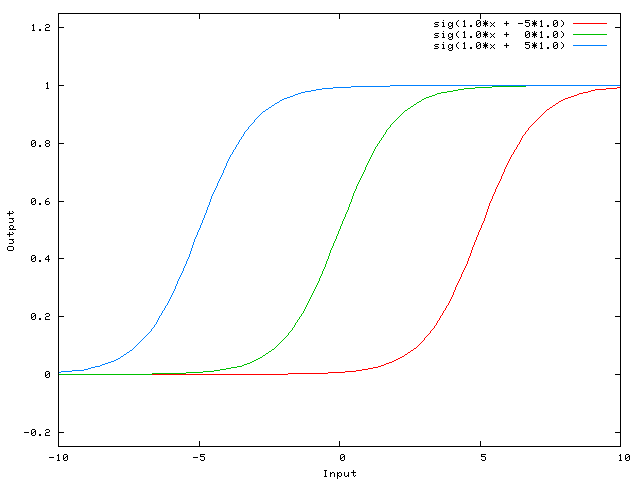
A more mathematical explanation is that despite that the steepness of the activation function can be modified easily without any bias, the bias is responsible for shifting along the X-axis the transfer function. In the following example, we have a one-to-one network and a sigmoid function, however, it can also be explained using the step transfer function described previously.
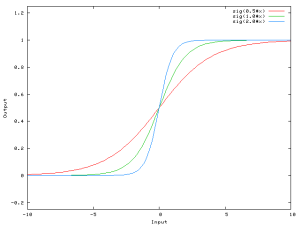
When we have an [latex]x[/latex] dependent argument, the steepness of the sigmoid function can be modified. However, it cannot go anywhere further than 0 when the input is 0. For this, we need a bias.
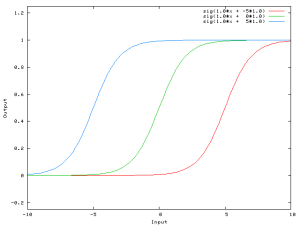
Now, the sigmoid curve can be shifted and we can, for example, get an output of 0 when the input is 2. Usually, the bias has a value of -1 or 1.
As a supervised learning algorithm, perceptron’s learning is based on a training set and a desired output for each input vector, and as a linear classifier, it can classify everything that is linearly separable. Now that we know how the perceptron works, it is time to see how it learns to classify data.
During the learning process, when the classifier receives input data and the classifier is able to classify it correctly, there is no need to make any adjustment. On the contrary, when there is a misclassified input, we need to update and readjust the weights applying the following formula:
[latex]w_i = w_i + \eta (t_i – y_i) x_i \quad[/latex]
(where w = weight, η = learning rate, t = target, y = output, x = input)
The learning rate plays a key role in perceptrons since it establishes the speed of perceptron’s learning. Before deciding which learning rate is more appropriate, note that a small learning rate may slow down considerably the speed of the learning algorithm and it will need more iterations and consequently more time and resources would be used whereas a big learning rate may make the algorithm jump from the minimum (as we can see in the picture) to climb the mountain that represents the error rate.
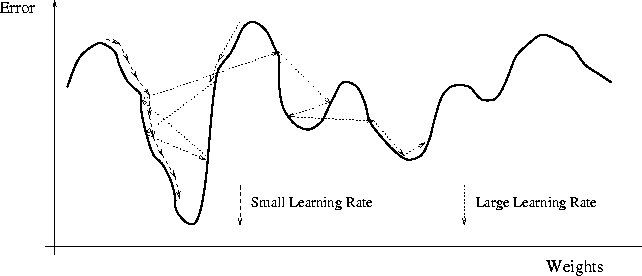
Usually, the learning rate is between 0.1 and 0.4 since the weights are small numbers, usually initialized randomly between 0 and 1. Finally, before showing practical examples and Matlab code, it is worth talking about normalization. Normalization it is necessary to keep small weight values which means easy computation. Without normalizing, the algorithm will neither work most of the times. It makes no sense to mix high values (say, values around many thousands) with small values (around 10^-8 values). There is not a unique way to normalize a set of values, but the first one showed me better results.
[latex]y = \frac{x-mean(x)}{var(x)} \\
y = \frac{x-min(x)}{max(x)-min(x)}[/latex]
Example 1: AND
In this case we have a very simple diagram with only two neurons as input and one as output. Additionally, we have a bias connected to the output.
| [latex]x_1[/latex] |
[latex]x_2[/latex] |
[latex]y[/latex] |
| 0 |
0 |
0 |
| 0 |
1 |
0 |
| 1 |
0 |
0 |
| 1 |
1 |
1 |
To solve this problem, we can iterate as many times as needed over our training set until we get no errors.
[latex]\displaystyle\sum_{i=0}^{N} w_i * x_i[/latex]
To learn, we apply the previous learning formula:
[latex]w_i = w_i + \eta (t_i – y_i) x_i[/latex]
After we finish iterating with no errors, we can build up the decision boundary using this formula:
[latex]y = \frac{-w_1*x + w_0}{w_2} \quad \to \quad w_2*y+w_1*x = w_0[/latex]
All elements at one side of the previous formula belong to a class whereas at the other side they belong to the other class.
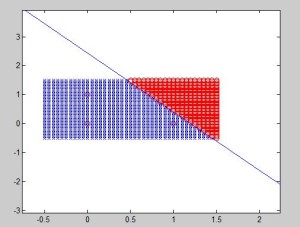
AND samples and the decision boundary were drawn. We could be sure about that the result will converge because the different classes are linearly separable (by a plane).
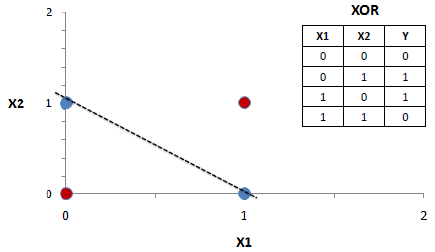
Example 2: XOR
This is the best example to see how Perceptron fails at classifying XOR since it is not possible to separate both classes using only one line, in contrast with other logic functions. If we try to use the perceptron here, it will endlessly try to converge.
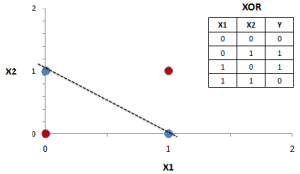
This problem can be actually solved by perceptron if we add an additional output neuron. You can think about it trying to imagine this problem in 3 dimensions. In that case, it would be linearly separable.
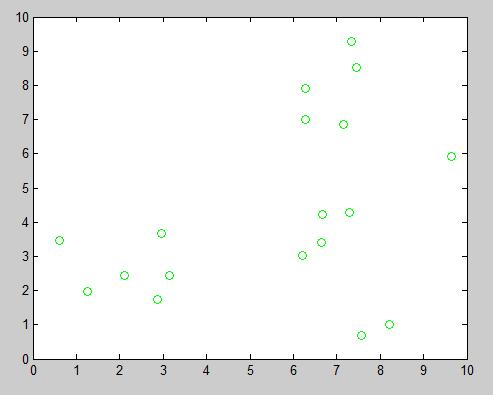
Example 3: Evolution of the decision boundary
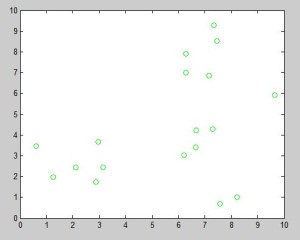
Let us use pseudorandom data:
data = 0.5 + (4-0.5).*rand(66,2);
data = [data ones(66,1)];
data2 = 5 + (10-5).*rand(34,2);
data2 = [data2 zeros(34,1)];
data = [data;data2];
Adding a plot in each iteration:
x = -3:13;
y = (-weights(2)*x+weights(1))/weights(3);
plot(x,y,'m');
We can see the evolution of the decision boundary:
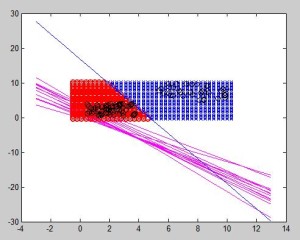
In this example, we can see that boundaries are not located at the same distance since different amounts of samples have been used. Using the same amount, the distance between the closest elements would be the same.
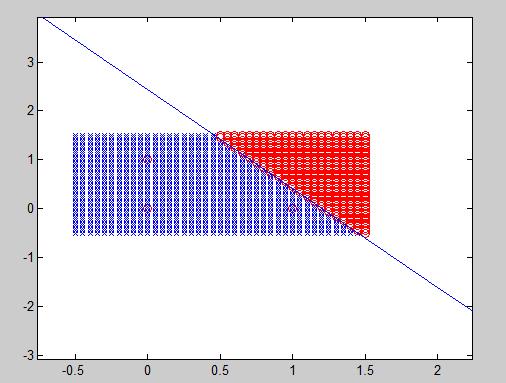
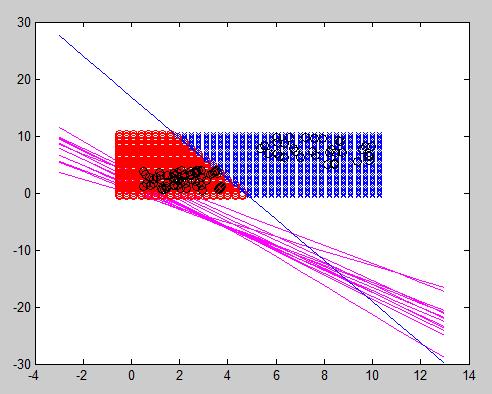
Example 4: Distinguishing more than 2 classes
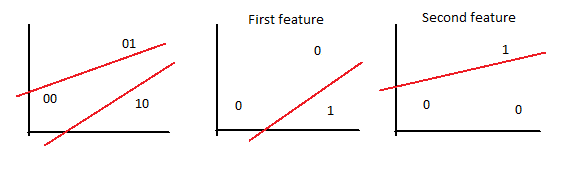
A naive attempt to simplify the amount of output neurons would be stating that 2 output neurons can classify up to 4 different classes since [latex]2^N = 4[/latex]. The 00 class would be class A, 01 class B, and so on. Nonetheless, the weights which go from input neurons to a certain output are able to classify just one element, so if 4 different classes are aimed to be distinguished, the same number of output neurons are needed.
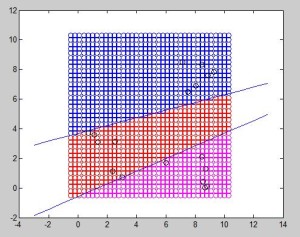
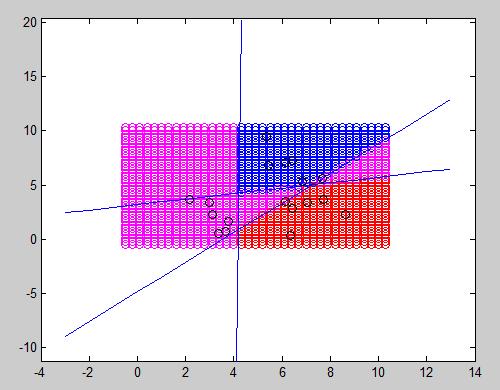
In the figure below, 3 different elements can be properly classified. The 2 output neurons perceptron can only distinguish one feature from another. In this example, 3 classes are differentiated: class B (blue), R and M, which respectively correspond to 01, 00 and 10 output.
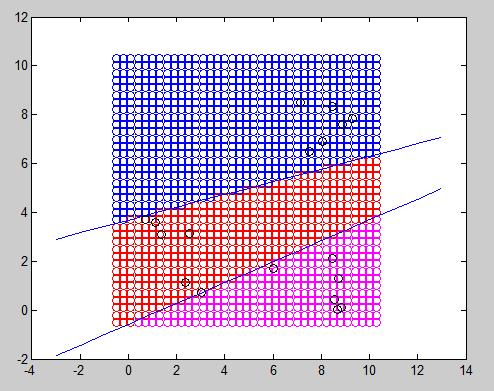
In this particular case, due to the position of each sample, it was possible to draw two straight lines through the whole training data. The next figure represents an example where unfortunately it is not possible to separate one feature from another. 6 samples from each of the 3 classes were chosen. In this case, the algorithm will endlessly try to converge without any valid result. In conclusion, for each feature to be distinguished, an output neuron is needed, but it still needs to be linearly separable.
Using as many output neurons as you want is not a panacea. In practice, as we can see below it may work sometimes when a straight line can separate a class from the rest of them (and even in this case, you can see that it has an odd behavior in some magenta regions that need to be specially treated.
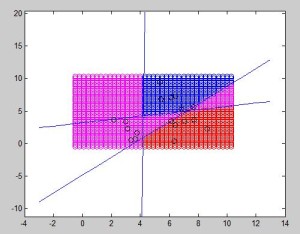
Finally, we have a case in which no line can be drawn to separate a class from the rest of them. It will always include a sample from other class. This algorithm definitely works better with few elements in each class because it will be able to linearly separate them, but this does not mean that it does a good work extrapolating new cases (for what the algorithm is suppose to be used).
Conclusions
Despite it seems that perceptrons can perform very poorly, they can be extremely powerful with datasets that undoubtedly are linearly separable since the algorithm is very simple and therefore they can be implemented in very basic systems such as an 8-bit board.
Additionally, perceptrons are academically important since their next evolution, the multilayer perceptron, is fairly used in many types of applications, from recognition/detection systems to control systems.
The code is provided in the Source code section.